La clasificación cartesiana es una clasificación adaptable, ya que clasifica los datos más rápido si los datos están parcialmente ordenados. De hecho, hay muy pocos algoritmos de clasificación que hagan uso de este hecho. Por ejemplo, considere la array {5, 10, 40, 30, 28}. Los datos de entrada también se ordenan parcialmente, ya que solo un intercambio entre «40» y «28» da como resultado un orden completamente ordenado.
Vea cómo la clasificación de árboles cartesianos aprovechará este hecho a continuación. A continuación se muestran los pasos utilizados para la clasificación.
Paso 1: construya un árbol cartesiano (min-heap) a partir de la secuencia de entrada dada.
Aplicaciones para la clasificación de árboles cartesianos:
- Es posible cuantificar cuánto más rápido se ejecutará el algoritmo que O(nlogn) usando una medida llamada oscilación . Prácticamente, la complejidad es cercana a O(nlog(Osc)) (donde Osc es oscilación).
- La oscilación es pequeña si la secuencia está parcialmente ordenada, por lo que el algoritmo funciona más rápido con secuencias parcialmente ordenadas.
 Paso 2: Comenzando desde la raíz del árbol cartesiano construido, empujamos los Nodes en una cola de prioridad. Luego, colocamos el Node en la parte superior de la cola de prioridad y empujamos a los elementos secundarios del Node emergente en la cola de prioridad en forma de pedido anticipado.
Paso 2: Comenzando desde la raíz del árbol cartesiano construido, empujamos los Nodes en una cola de prioridad. Luego, colocamos el Node en la parte superior de la cola de prioridad y empujamos a los elementos secundarios del Node emergente en la cola de prioridad en forma de pedido anticipado.
- Coloque el Node en la parte superior de la cola de prioridad y agréguelo a una lista.
- Empuje primero el elemento secundario izquierdo del Node reventado (si está presente).
- Empuje el elemento secundario derecho del Node reventado a continuación (si está presente).


¿Cómo construir un árbol cartesiano (min-heap)?
Construir un montón mínimo es similar a construir un árbol cartesiano (montón máximo) (discutido en una publicación anterior ), excepto por el hecho de que ahora escaneamos hacia arriba desde el padre del Node hasta la raíz del árbol hasta que se encuentra un Node cuyo valor es más pequeño (y no más grande como en el caso de un árbol cartesiano de montón máximo) que el actual y, a continuación, reconfigurar los enlaces en consecuencia para construir el árbol cartesiano de montón mínimo.
¿Por qué no usar solo la cola de prioridad?
Uno podría preguntarse si el uso de la cola de prioridad daría como resultado datos ordenados si simplemente insertamos los números de la array de entrada uno por uno en la cola de prioridad (es decir, sin construir el árbol cartesiano). Pero el tiempo empleado difiere mucho. Supongamos que tomamos la array de entrada: {5, 10, 40, 30, 28} Si simplemente insertamos los números de la array de entrada uno por uno (sin usar un árbol cartesiano), es posible que tengamos que desperdiciar muchas operaciones para ajustar la orden de la cola cada vez que insertamos los números (al igual que un montón típico realiza esas operaciones cuando se inserta un nuevo número, ya que la cola de prioridad no es más que un montón). Considerando que, aquí podemos ver que usar un árbol cartesiano tomó solo 5 operaciones (vea las dos figuras anteriores en las que estamos presionando y sacando continuamente los Nodes del árbol cartesiano), que es lineal ya que también hay 5 números en la array de entrada. Entonces vemos que el mejor caso de clasificación de árbol cartesiano es O (n), una cosa en la que la clasificación de montón requerirá muchas más operaciones, porque no aprovecha el hecho de que los datos de entrada están parcialmente ordenados.
¿Por qué reservar el recorrido?
La respuesta a esto es que, dado que el árbol cartesiano es básicamente una estructura de datos de montón, sigue todas las propiedades de un montón. Por lo tanto, el Node raíz siempre es más pequeño que sus dos hijos. Por lo tanto, usamos una moda de pedido anticipado de hacer estallar y empujar como en esto, el Node raíz siempre se empuja antes que sus hijos dentro de la cola de prioridad y dado que el Node raíz siempre es menor que sus dos hijos, por lo que no tiene que hacer operaciones adicionales dentro de la cola de prioridad. Consulte la siguiente figura para una mejor comprensión . Enfoque :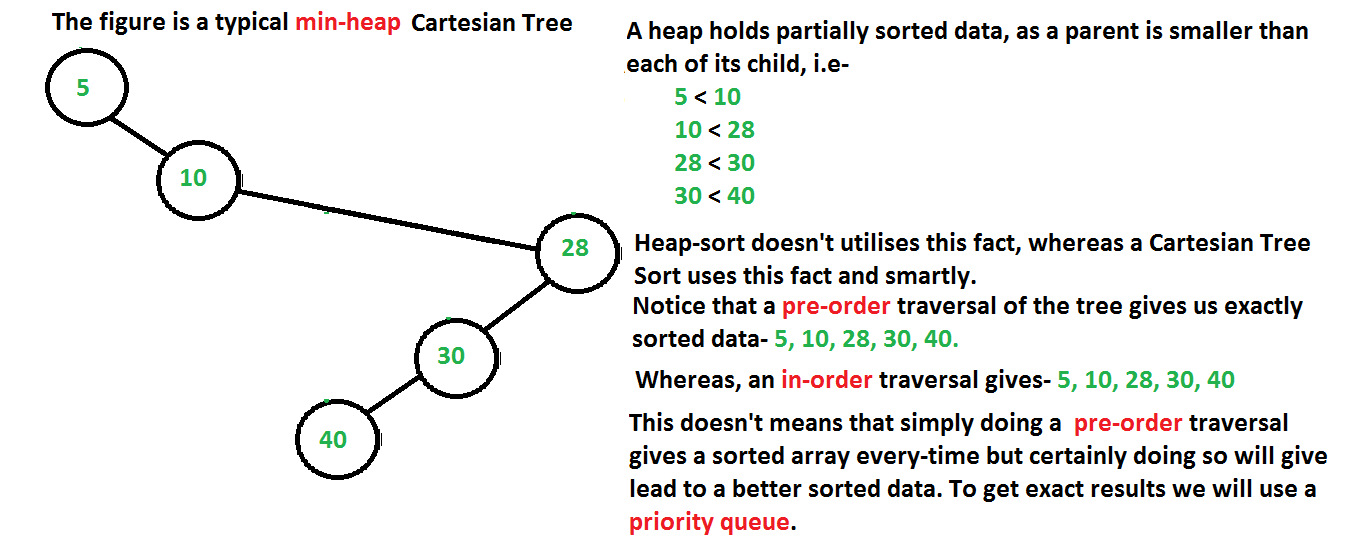
- Construya un árbol cartesiano para la secuencia dada.
- Cree una cola de prioridad , que al principio tenga solo la raíz del árbol cartesiano.
- Extraiga el valor mínimo x de la cola de prioridad
- Agregar x a la secuencia de salida
- Empuje el hijo izquierdo de x del árbol cartesiano a la cola de prioridad.
- Empuje el hijo derecho de x del árbol cartesiano a la cola de prioridad.
- Si la cola de prioridad no está vacía, vaya de nuevo al paso 3.
A continuación se muestra la implementación del enfoque anterior:
CPP
// A C++ program to implement Cartesian Tree sort
// Note that in this program we will build a min-heap
// Cartesian Tree and not max-heap.
#include<bits/stdc++.h>
using namespace std;
/* A binary tree node has data, pointer to left child
and a pointer to right child */
struct Node
{
int data;
Node *left, *right;
};
// Creating a shortcut for int, Node* pair type
typedef pair<int, Node*> iNPair;
// This function sorts by pushing and popping the
// Cartesian Tree nodes in a pre-order like fashion
void pQBasedTraversal(Node* root)
{
// We will use a priority queue to sort the
// partially-sorted data efficiently.
// Unlike Heap, Cartesian tree makes use of
// the fact that the data is partially sorted
priority_queue <iNPair, vector<iNPair>, greater<iNPair>> pQueue;
pQueue.push (make_pair (root->data, root));
// Resembles a pre-order traverse as first data
// is printed then the left and then right child.
while (! pQueue.empty())
{
iNPair popped_pair = pQueue.top();
printf("%d ", popped_pair.first);
pQueue.pop();
if (popped_pair.second->left != NULL)
pQueue.push (make_pair(popped_pair.second->left->data,
popped_pair.second->left));
if (popped_pair.second->right != NULL)
pQueue.push (make_pair(popped_pair.second->right->data,
popped_pair.second->right));
}
return;
}
Node *buildCartesianTreeUtil(int root, int arr[],
int parent[], int leftchild[], int rightchild[])
{
if (root == -1)
return NULL;
Node *temp = new Node;
temp->data = arr[root];
temp->left = buildCartesianTreeUtil(leftchild[root],
arr, parent, leftchild, rightchild);
temp->right = buildCartesianTreeUtil(rightchild[root],
arr, parent, leftchild, rightchild);
return temp ;
}
// A function to create the Cartesian Tree in O(N) time
Node *buildCartesianTree(int arr[], int n)
{
// Arrays to hold the index of parent, left-child,
// right-child of each number in the input array
int parent[n], leftchild[n], rightchild[n];
// Initialize all array values as -1
memset(parent, -1, sizeof(parent));
memset(leftchild, -1, sizeof(leftchild));
memset(rightchild, -1, sizeof(rightchild));
// 'root' and 'last' stores the index of the root and the
// last processed of the Cartesian Tree.
// Initially we take root of the Cartesian Tree as the
// first element of the input array. This can change
// according to the algorithm
int root = 0, last;
// Starting from the second element of the input array
// to the last on scan across the elements, adding them
// one at a time.
for (int i = 1; i <= n - 1; i++)
{
last = i-1;
rightchild[i] = -1;
// Scan upward from the node's parent up to
// the root of the tree until a node is found
// whose value is smaller than the current one
// This is the same as Step 2 mentioned in the
// algorithm
while (arr[last] >= arr[i] && last != root)
last = parent[last];
// arr[i] is the smallest element yet; make it
// new root
if (arr[last] >= arr[i])
{
parent[root] = i;
leftchild[i] = root;
root = i;
}
// Just insert it
else if (rightchild[last] == -1)
{
rightchild[last] = i;
parent[i] = last;
leftchild[i] = -1;
}
// Reconfigure links
else
{
parent[rightchild[last]] = i;
leftchild[i] = rightchild[last];
rightchild[last]= i;
parent[i] = last;
}
}
// Since the root of the Cartesian Tree has no
// parent, so we assign it -1
parent[root] = -1;
return (buildCartesianTreeUtil (root, arr, parent,
leftchild, rightchild));
}
// Sorts an input array
int printSortedArr(int arr[], int n)
{
// Build a cartesian tree
Node *root = buildCartesianTree(arr, n);
printf("The sorted array is-\n");
// Do pr-order traversal and insert
// in priority queue
pQBasedTraversal(root);
}
/* Driver program to test above functions */
int main()
{
/* Given input array- {5,10,40,30,28},
it's corresponding unique Cartesian Tree
is-
5
\
10
\
28
/
30
/
40
*/
int arr[] = {5, 10, 40, 30, 28};
int n = sizeof(arr)/sizeof(arr[0]);
printSortedArr(arr, n);
return(0);
}
The sorted array is- 5 10 28 30 40
Complejidad del tiempo:
- O (n) comportamiento en el mejor de los casos (cuando los datos de entrada están parcialmente ordenados),
- O(n log n) comportamiento en el peor de los casos (cuando los datos de entrada no están parcialmente ordenados)
Espacio auxiliar: utilizamos una cola de prioridad y una estructura de datos de árbol cartesiano. Ahora, en cualquier momento, el tamaño de la cola de prioridad no excede el tamaño de la array de entrada, ya que estamos constantemente empujando y abriendo los Nodes.
Por lo tanto, estamos usando el espacio auxiliar O(n).
Echa un vistazo al curso de autoaprendizaje de DSA
Este artículo es una contribución de Rachit Belwariar . Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo y enviarlo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks. Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA