Para clasificar las filas de Pandas DataFrame, podemos usar el DataFrame.rank() método que devuelve una clasificación de cada índice respectivo de una serie pasada. El rango se devuelve sobre la base de la posición después de la clasificación.
Ejemplo 1 :
Aquí crearemos un marco de datos de películas y las clasificaremos según sus calificaciones.
# import the required packages
import pandas as pd
# Define the dictionary for converting to dataframe
movies = {'Name': ['The Godfather', 'Bird Box', 'Fight Club'],
'Year': ['1972', '2018', '1999'],
'Rating': ['9.2', '6.8', '8.8']}
df = pd.DataFrame(movies)
print(df)
Producción: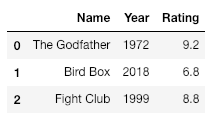
# Create a column Rating_Rank which contains
# the rank of each movie based on rating
df['Rating_Rank'] = df['Rating'].rank(ascending = 1)
# Set the index to newly created column, Rating_Rank
df = df.set_index('Rating_Rank')
print(df)
Producción: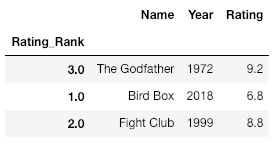
# Sort the dataFrame based on the index df = df.sort_index() print(df)
Salida: 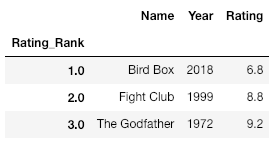
Ejemplo #2
Tomemos un ejemplo de calificaciones obtenidas por 4 estudiantes. Clasificaremos a los estudiantes según la calificación más alta que hayan obtenido.
# Create a dictionary with student details
student_details = {'Name':['Raj', 'Raj', 'Raj', 'Aravind', 'Aravind', 'Aravind',
'John', 'John', 'John', 'Arjun', 'Arjun', 'Arjun'],
'Subject':['Maths', 'Physics', 'Chemistry', 'Maths', 'Physics',
'Chemistry', 'Maths', 'Physics', 'Chemistry', 'Maths',
'Physics', 'Chemistry'],
'Marks':[80, 90, 75, 60, 40, 60, 80, 55, 100, 90, 75, 70]
}
# Convert dictionary to a DataFrame
df = pd.DataFrame(student_details)
print(df)
Producción: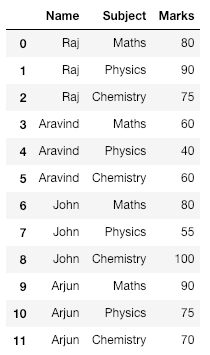
# Create a new column with Marks
# ranked in descending order
df['Mark_Rank'] = df['Marks'].rank(ascending = 0)
# Set index to newly created column
df = df.set_index('Mark_Rank')
print(df)
Producción: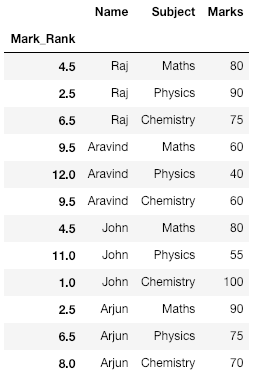
# Sort the DataFrame based on the index df = df.sort_index() print(df)
Producción: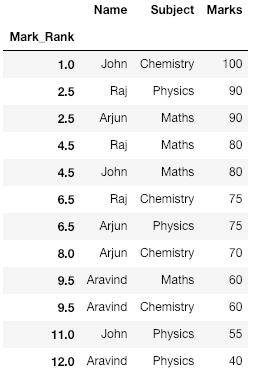
Explicación:
Observe aquí que tenemos a Raj y Arjun obteniendo 90 puntos cada uno y, por lo tanto, obtienen el puesto 2.5 (promedio del segundo y tercer puesto, es decir, los dos puestos que comparten). Esto también se puede ver para otras marcas en la tabla.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA