R es un lenguaje de programación muy dinámico y versátil para la ciencia de datos. Este artículo trata sobre la clasificación en R. Generalmente, los clasificadores en R se utilizan para predecir información relacionada con categorías específicas, como reseñas o calificaciones, como bueno, mejor o peor.
Varios clasificadores son:
- Árboles de decisión
- Clasificadores Naive Bayes
- Clasificadores K-NN
- Máquinas de vectores de soporte (SVM)
Clasificador de árboles de decisión
Básicamente es un gráfico para representar opciones. Los Nodes o vértices del gráfico representan un evento y los bordes del gráfico representan las condiciones de decisión. Su uso común es en aplicaciones de Machine Learning y Data Mining.
Aplicaciones:
Clasificación de correo electrónico no deseado/no deseado, predicción de si un tumor es canceroso o no. Por lo general, un modelo se construye con datos anotados, también llamados conjuntos de datos de entrenamiento. Luego, se utiliza un conjunto de datos de validación para verificar y mejorar el modelo. R tiene paquetes que se utilizan para crear y visualizar árboles de decisión.
El paquete R «party» se usa para crear árboles de decisión.
Dominio:
install.packages("party")
Python3
# Load the party package. It will automatically load other # dependent packages. library(party) # Create the input data frame. input.data <- readingSkills[c(1:105), ] # Give the chart file a name. png(file = "decision_tree.png") # Create the tree. output.tree <- ctree( nativeSpeaker ~ age + shoeSize + score, data = input.dat) # Plot the tree. plot(output.tree) # Save the file. dev.off()
Producción:
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich
Clasificador bayesiano ingenuo
La clasificación Naïve Bayes es un método de clasificación general que utiliza un enfoque de probabilidad, por lo que también se conoce como enfoque probabilístico basado en el teorema de Bayes con la suposición de independencia entre las características. El modelo está entrenado en un conjunto de datos de entrenamiento para hacer predicciones mediante la función predict() .
Fórmula:
P(A|B)=P(B|A)×P(A)P(B)
Es un método de muestra en los métodos de aprendizaje automático, pero puede ser útil en algunos casos. El entrenamiento es fácil y rápido que solo requiere considerar cada predictor en cada clase por separado.
Aplicación:
Se utiliza generalmente en análisis sentimental.
Python3
library(caret) ## Warning: package 'caret' was built under R version 3.4.3 set.seed(7267166) trainIndex = createDataPartition(mydata$prog, p = 0.7)$Resample1 train = mydata[trainIndex, ] test = mydata[-trainIndex, ] ## check the balance print(table(mydata$prog)) ## ## academic general vocational ## 105 45 50 print(table(train$prog))
Producción:
## Naive Bayes Classifier for Discrete Predictors ## ## Call: ## naiveBayes.default(x = X, y = Y, laplace = laplace) ## ## A-priori probabilities: ## Y ## academic general vocational ## 0.5248227 0.2269504 0.2482270 ## ## Conditional probabilities: ## science ## Y [, 1] [, 2] ## academic 54.21622 9.360761 ## general 52.18750 8.847954 ## vocational 47.31429 9.969871 ## ## socst ## Y [, 1] [, 2] ## academic 56.58108 9.635845 ## general 51.12500 8.377196 ## vocational 44.82857 10.279865
Clasificador K-NN
Otro clasificador utilizado es el clasificador K-NN. En el reconocimiento de patrones, el algoritmo del vecino más cercano k (k-NN) es un método no paramétrico generalmente utilizado para clasificación y regresión. En ambos casos, la entrada consta de los k ejemplos de entrenamiento más cercanos en el espacio de características. En la clasificación k-NN, la salida es una pertenencia a una clase.
Aplicaciones:
se utiliza en una variedad de aplicaciones, como pronósticos económicos, compresión de datos y genética.
Ejemplo:
Python3
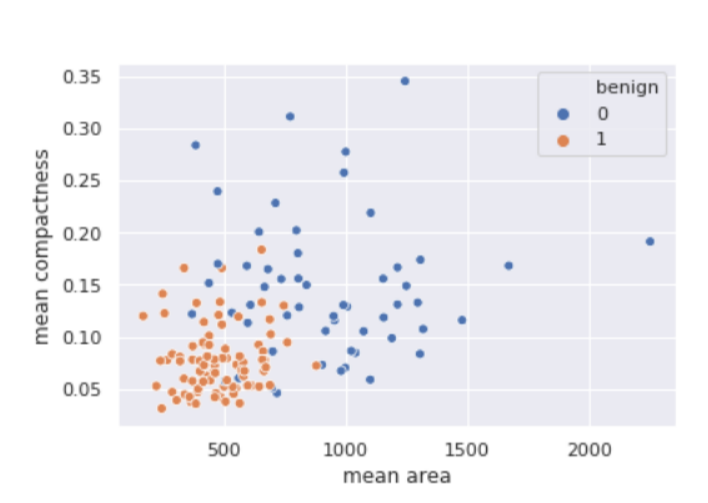
# Write Python3 code here import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.datasets import load_breast_cancer from sklearn.metrics import confusion_matrix from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split import seaborn as sns sns.set() breast_cancer = load_breast_cancer() X = pd.DataFrame(breast_cancer.data, columns = breast_cancer.feature_names) X = X[['mean area', 'mean compactness']] y = pd.Categorical.from_codes(breast_cancer.target, breast_cancer.target_names) y = pd.get_dummies(y, drop_first = True) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1) sns.scatterplot( x ='mean area', y ='mean compactness', hue ='benign', data = X_test.join(y_test, how ='outer') )
Producción:
Máquinas de vectores de soporte (SVM)
Una máquina de vectores de soporte (SVM) es un algoritmo de aprendizaje automático binario supervisado que utiliza algoritmos de clasificación para problemas de clasificación de dos grupos. Después de proporcionar a un modelo SVM conjuntos de datos de entrenamiento etiquetados para cada categoría, pueden categorizar el texto nuevo.
Principalmente SVM se utiliza para problemas de clasificación de texto. Clasifica los datos no vistos. Es ampliamente utilizado que Naive Bayes. SVM id suele ser un algoritmo de clasificación rápido y fiable que funciona muy bien con una cantidad limitada de datos.
Aplicaciones:
las SVM tienen una serie de aplicaciones en varios campos como la bioinformática, para clasificar genes, etc.
Ejemplo:
Python3
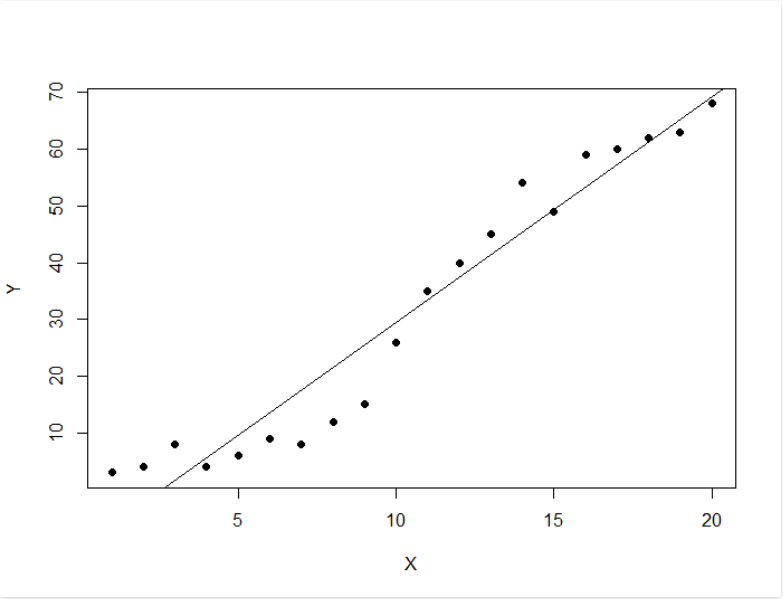
# Load the data from the csv file dataDirectory <- "D:/" # put your own folder here data <- read.csv(paste(dataDirectory, 'regression.csv', sep =""), header = TRUE) # Plot the data plot(data, pch = 16) # Create a linear regression model model <- lm(Y ~ X, data) # Add the fitted line abline(model)
Producción:
Publicación traducida automáticamente
Artículo escrito por rutujakawade24 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA