Los únicos tipos de datos compuestos nativos del inglés sencillo osmosiano son los registros y las listas con enlaces dobles. Cuando necesitamos ordenar una lista, usamos la ordenación de combinación recursiva simple que describiré a continuación. Pero primero necesitamos algo para ordenar. Clasifiquemos frutas y comencemos con una definición de tipo:
A fruit is a thing with a name.Cuando la palabra «cosa» aparece en una definición de tipo, nuestro compilador hace un poco de magia detrás de escena para hacer que las cosas (juego de palabras) sean más poderosas y flexibles. La definición anterior, por ejemplo, en realidad hace que se definan los siguientes tipos de datos:
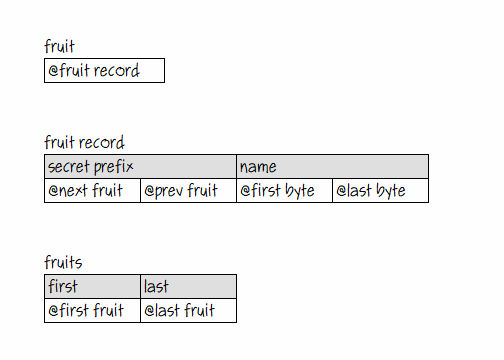
Entonces, una fruta no es más que un puntero que contiene la dirección de un registro de frutas.
Y cada registro de frutas de 16 bytes tiene un prefijo oculto de 8 bytes con dos punteros para vincular estos registros en listas, junto con el nombre de la fruta, que es una string. Las strings en inglés simple se almacenan en el Heap y pueden tener cualquier longitud. Entonces, el nombre en el registro de frutas es en realidad solo dos punteros al primer y último byte de la string en el montón, respectivamente. La memoria de strings se administra automáticamente, pero la memoria de objetos la administra el programador.
El tercer tipo generado por el compilador sirve como ancla para las listas de Fruit Records. Estas listas se denominan simplemente (e intuitivamente) Fruits, el plural de Fruit.
Ahora agreguemos algunas frutas a una lista, en orden aleatorio, y clasifíquelas. Aquí están las oraciones de nivel superior en nuestro programa de prueba:
To run:
Start up.
Create some fruits.
Write the fruits on the console.
Skip a line on the console.
Sort the fruits.
Write the fruits on the console.
Destroy the fruits.
Wait for the escape key.
Shut down.Y aquí están las rutinas que se llamarán para “Crear algunas frutas”:
To create some fruits:
Add "banana" to the fruits.
Add "apple" to the fruits.
Add "orange" to the fruits.
Add "bacon" to the fruits.
Add "pineapple" to the fruits.
Add "pomegranate" to the fruits.
Add "tomato" to the fruits.
Add "grape" to the fruits.
Add "fig" to the fruits.
Add "date" to the fruits.
To add a name to some fruits:
Allocate memory for a fruit.
Put the name into the fruit's name.
Append the fruit to the fruits.Ahora estamos listos para ordenar. Esta es la rutina de clasificación:
To sort some fruits:
If the fruits' first is the fruits' last, exit.
Split the fruits into some left fruits and some right fruits.
Sort the left fruits.
Sort the right fruits.
Loop.
Put the left fruits' first into a left fruit.
Put the right fruits' first into a right fruit.
If the left fruit is nil, append the right fruits to the fruits; exit.
If the right fruit is nil, append the left fruits to the fruits; exit.
If the left fruit's name is greater than the right fruit's name,
move the right fruit from the right fruits to the fruits; repeat.
Move the left fruit from the left fruits to the fruits.
Repeat.Cuando ejecutamos este programa, la salida en la consola se ve así:

¿Pero es rápido? Veamos usando este programa de prueba modificado:
To run:
Start up.
Write "Working..." on the console.
Put 10000 into a count.
Create some fruits using "apple" and the count.
Start a timer. Sort the fruits. Stop the timer.
Write the timer then " milliseconds for " then the count on the console.
Destroy the fruits.
Put 100000 into the count.
Create the fruits using "apple" and the count.
Start the timer. Sort the fruits. Stop the timer.
Write the timer then " milliseconds for " then the count on the console.
Destroy the fruits.
Put 1000000 into the count.
Create the fruits using "apple" and the count.
Start the timer. Sort the fruits. Stop the timer.
Write the timer then " milliseconds for " then the count on the console.
Destroy the fruits.
Wait for the escape key.
Shut down.Los frutos esta vez, al principio, se ven así:
apple 0010000
apple 0009999
apple 0009998
...Y la salida en la consola se ve así:
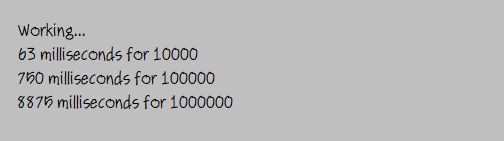
No del todo lineal, lo admito. Pero tampoco exponencialmente malo. Diez veces más registros tardan aproximadamente diez veces más en clasificarse. Hay una forma técnica de decir esto usando grandes «O» y pequeñas «n» y «logs» y esas cosas, pero los programadores en lenguaje sencillo generalmente no piensan de esa manera. Y es estable, como esperaría un programador de lenguaje sencillo: los registros con valores de clasificación duplicados conservan su secuencia original.
Cosas buenas, sencillas y útiles.
Publicación traducida automáticamente
Artículo escrito por Gerry.Rzeppa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA