K-Nearest Neighbor o K-NN es un algoritmo de clasificación no lineal supervisado. K-NN es un algoritmo no paramétrico, es decir, no hace ninguna suposición sobre los datos subyacentes o su distribución. Es uno de los algoritmos más simples y ampliamente utilizados que depende de su valor k (vecinos) y encuentra sus aplicaciones en muchas industrias como la industria financiera, la industria de la salud, etc.
Teoría
En el algoritmo KNN, K especifica el número de vecinos y su algoritmo es el siguiente:
- Elija el número K de vecino.
- Tome el vecino más cercano K del punto de datos desconocido según la distancia.
- Entre los K-vecinos, Cuente el número de puntos de datos en cada categoría.
- Asigne el nuevo punto de datos a una categoría, donde contó la mayoría de los vecinos.
Para el clasificador Vecino más cercano, la distancia entre dos puntos se expresa en forma de Distancia euclidiana.
Ejemplo:
considere un conjunto de datos que contiene dos características, rojo y azul, y las clasificamos. Aquí K es 5, es decir, estamos considerando 5 vecinos según la distancia euclidiana.
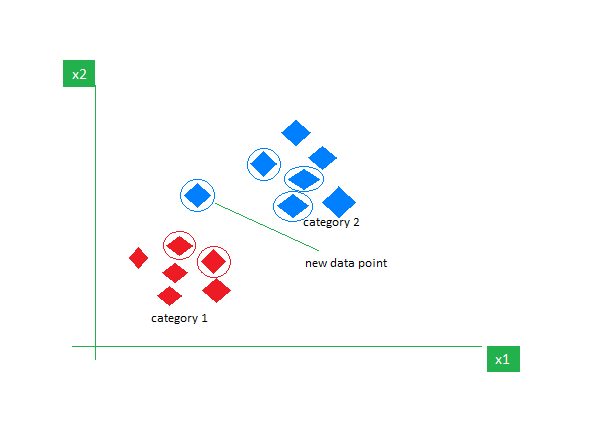
Entonces, cuando ingresa un nuevo punto de datos, de 5 vecinos, 3 son azules y 2 son rojos. Asignamos el nuevo punto de datos a la categoría con más vecinos, es decir, Azul.
El conjunto de datos
IrisEl conjunto de datos consta de 50 muestras de cada una de las 3 especies de Iris (Iris setosa, Iris virginica, Iris versicolor) y un conjunto de datos multivariante introducido por el estadístico y biólogo británico Ronald Fisher en su artículo de 1936 El uso de mediciones múltiples en problemas taxonómicos. Se midieron cuatro características de cada muestra, es decir, la longitud y el ancho de los sépalos y pétalos y, basándose en la combinación de estas cuatro características, Fisher desarrolló un modelo discriminante lineal para distinguir las especies entre sí.
# Loading data data(iris) # Structure str(iris)

Ejecución de K Vecino más cercano en el conjunto de datos
Usando el algoritmo K-Nearest Neighbor en el conjunto de datos que incluye 11 personas y 6 variables o atributos.
# Installing Packages
install.packages("e1071")
install.packages("caTools")
install.packages("class")
# Loading package
library(e1071)
library(caTools)
library(class)
# Loading data
data(iris)
head(iris)
# Splitting data into train
# and test data
split <- sample.split(iris, SplitRatio = 0.7)
train_cl <- subset(iris, split == "TRUE")
test_cl <- subset(iris, split == "FALSE")
# Feature Scaling
train_scale <- scale(train_cl[, 1:4])
test_scale <- scale(test_cl[, 1:4])
# Fitting KNN Model
# to training dataset
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 1)
classifier_knn
# Confusiin Matrix
cm <- table(test_cl$Species, classifier_knn)
cm
# Model Evaluation - Choosing K
# Calculate out of Sample error
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 3
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 3)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 5
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 5)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 7
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 7)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 15
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 15)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 19
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 19)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
Producción:
- Modelo clasificador_knn(k=1):
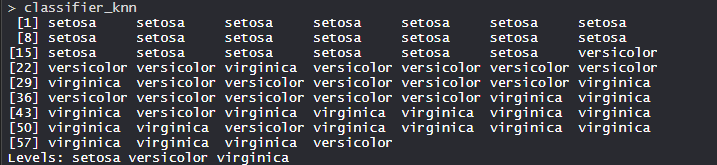
El modelo KNN está equipado con un tren, una prueba y un valor k. Además, la función Clasificador de especies está incluida en el modelo.
- Array de confusión:
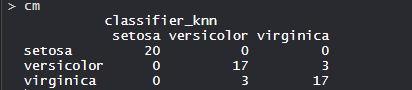
Entonces, 20 Setosa se clasifican correctamente como Setosa. De 20 Versicolor, 17 Versicolor se clasifican correctamente como Versicolor y 3 se clasifican como virginica. De 20 virginica, 17 virginica se clasifican correctamente como virginica y 3 se clasifican como Versicolor.
- Evaluación del modelo:
(k=1)
El modelo logró una precisión del 90% con k es 1.
(K=3)

El modelo logró una precisión del 88,33 % con k es 3, que es menor que cuando k era 1.
(K=5)

El modelo logró una precisión del 91,66 % con k es 5, que es más que cuando k era 1 y 3.
(K=7)

El modelo logró una precisión del 93,33 % con k es 7, que es más que cuando k era 1, 3 y 5.
(K=15)

El modelo logró una precisión del 95% con k es 15, que es más que cuando k era 1, 3, 5 y 7.
(K=19)

El modelo logró una precisión del 95 % con k es 19, que es más que cuando k era 1, 3, 5 y 7. Es la misma precisión cuando k era 15, lo que significa que ahora aumentar los valores de k no afecta la precisión.
Por lo tanto, K Nearest Neighbor se usa ampliamente en la industria.