En este artículo, vamos a ver cómo clasificar la variable por grupo usando dplyr en el lenguaje de programación R.
El paquete dplyr en R se usa para realizar mutaciones y manipulaciones de datos en R. Es particularmente útil para trabajar con marcos de datos y tablas de datos. El paquete se puede descargar e instalar en el directorio de trabajo usando el siguiente comando:
install.packages("dplyr")
Ordenar por rango en orden ascendente
El método de arreglo() se invoca para organizar los datos del marco de datos en orden ascendente o descendente. Se utiliza para reordenar las filas del marco de datos en función de los nombres de las variables.
arrange(col-name)
A esto le sigue la aplicación del método group_by que toma como argumentos el conjunto de nombres de columna que se utilizan para agrupar los datos. Puede comprender una o más columnas.
group_by(col-name1, col-name2..)
Luego, el método mutate() se puede aplicar al marco de datos para realizar manipulaciones o modificaciones cambiando la orientación de los datos almacenados en el marco de datos. El método rank() se utiliza para asignar clasificaciones numéricas a los valores de datos asignados a los grupos asignados. De forma predeterminada, el rango se muestra en orden ascendente.
rank(col-name)
Código:
R
library("dplyr")
# creating a data frame
data_frame <- data.frame(col1 = rep(letters[1:3],each = 4),
col2 = 1:12)
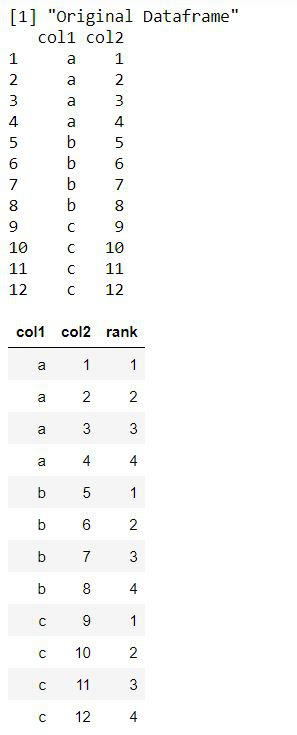
print ("Original Dataframe")
print (data_frame)
data_frame %>% arrange(col1, col2) %>%
group_by(col1) %>%
mutate(rank = rank(col2))
Producción:
Ordenar por rango en orden descendente
Para mostrar los rangos en orden descendente, el nombre de la columna se antepone con un signo menos. Esto muestra los rangos numéricos del vector en orden decreciente. El nuevo nombre de columna se puede asignar a la salida de este método. El marco de datos de salida contiene una columna adicional con el mismo nombre que el nombre asignado.
R
library("dplyr")
# creating a data frame
data_frame <- data.frame(col1 = rep(letters[1:3],each = 4),
col2 = 1:12)
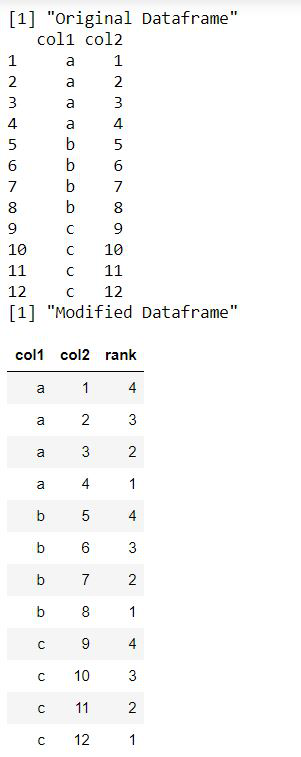
print ("Original Dataframe")
print (data_frame)
# ranking by col1 variable
print ("Modified Dataframe")
# ranking in descending order
data_frame %>% arrange(col1, col2) %>%
group_by(col1) %>%
mutate(rank = rank(-col2))
Producción:
Publicación traducida automáticamente
Artículo escrito por mallikagupta90 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA