En este artículo, vamos a ver cómo fusionar el marco de datos por nombres de columna usando la fusión en el lenguaje de programación R.
La función merge() en base R se puede usar para fusionar marcos de datos de entrada por columnas comunes o nombres de filas. La función merge() conserva todos los nombres de fila de los marcos de datos, comportándose de manera similar a la unión interna. Los marcos de datos se combinan en orden de aparición en la llamada de función de entrada.
Sintaxis: merge(x, y, by, all)
Argumentos:
- x, y – Los marcos de datos de entrada
- by: especificaciones de las columnas utilizadas para la fusión. En caso de fusionarse usando nombres de fila, el atributo by usa el valor ‘row.names’.
- todos – lógico verdadero o falso.
Ejemplo 1: fusionar dos marcos de datos por columnas
Se pueden fusionar dos marcos de datos usando las columnas comunes, en ambos marcos de datos. La columna que se usará para fusionar se puede especificar en el parámetro «por» durante la llamada a la función. El marco de datos de salida produce las filas equivalentes a las entradas comunes que se encuentran en las columnas especificadas en el argumento «por».
R
# creating first dataframe
df1 <- data.frame(col1 = LETTERS[1:6],
col2a = c(5:10),
col3a = TRUE)
print ("First DataFrame")
print (df1)
df2 <- data.frame(col1 = LETTERS[4:8],
col2b= c(4:8),
col3b = FALSE)
print ("Second DataFrame")
print (df2)
df_merge <- merge(df1,df2,by="col1")
print("Merged DataFrame")
print (df_merge)
Producción:

Ejemplo 2: combinar marco de datos con valores faltantes
Para conservar todos los valores del primer marco de datos, independientemente de si tienen valores comunes o no en el parámetro «por», establecemos all.x = verdadero. Los valores faltantes que pertenecen al segundo marco de datos se agregan con un valor NA.
R
# creating first dataframe
df1 <- data.frame(col1 = LETTERS[1:6],
col2a = c(5:10),
col3a = TRUE)
print ("First DataFrame")
print (df1)
df2 <- data.frame(col1 = LETTERS[4:8],
col2b= c(4:8),
col3b = FALSE)
print ("Second DataFrame")
print (df2)
df_merge <- merge(df1, df2, by = "col1",
all.x = TRUE)
print("Merged DataFrame")
print (df_merge)
Producción:

Para conservar todos los valores del segundo marco de datos, independientemente de si tienen valores comunes o no en el parámetro «by», establecemos all.y = true. Los valores faltantes que pertenecen a las primeras columnas del marco de datos se agregan con un valor NA.
R
# creating first dataframe
df1 <- data.frame(col1 = LETTERS[1:6],
col2a = c(5:10),
col3a = TRUE)
print ("First DataFrame")
print (df1)
df2 <- data.frame(col1 = LETTERS[4:8],
col2b= c(4:8),
col3b = FALSE)
print ("Second DataFrame")
print (df2)
df_merge <- merge(df1, df2, by = "col1",
all.y = TRUE)
print("Merged DataFrame")
print (df_merge)
Producción:
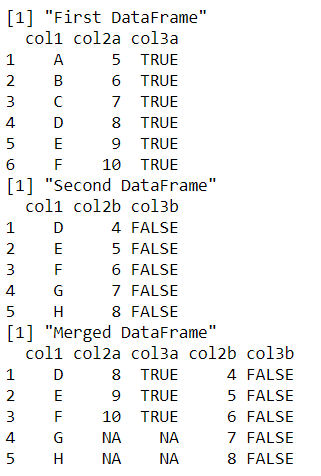
El siguiente código ilustra el uso cuando se deben conservar todas las filas de ambos marcos de datos de entrada.
R
# creating first dataframe
df1 <- data.frame(col1 = LETTERS[1:6],
col2a = c(5:10),
col3a = TRUE)
print ("First DataFrame")
print (df1)
df2 <- data.frame(col1 = LETTERS[4:8],
col2b= c(4:8),
col3b = FALSE)
print ("Second DataFrame")
print (df2)
df_merge <- merge(df1,df2,by="col1",all.x = TRUE, all.y=TRUE)
print("Merged DataFrame")
print (df_merge)
Producción:
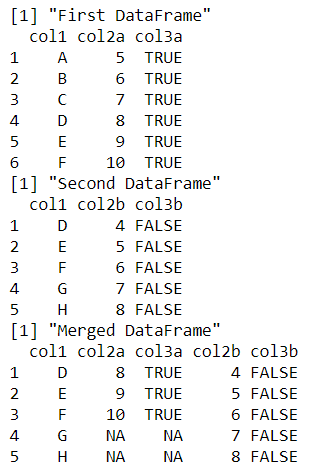
Ejemplo 3: combinar más de dos marcos de datos
También se pueden fusionar más de dos marcos de datos. Sin embargo, los marcos de datos se fusionan usando la llamada al método merge(), dos a la vez en el orden en que aparecen en la llamada a la función. Por lo tanto, si se van a fusionar n marcos de datos, se requieren n-1 llamadas de función.
R
# creating first dataframe
df1 <- data.frame(col1 = LETTERS[1:6],
col2a = c(5:10),
col3a = TRUE)
print ("First DataFrame")
print (df1)
df2 <- data.frame(col1 = LETTERS[4:8],
col2b= c(4:8),
col3b = FALSE)
print ("Second DataFrame")
print (df2)
df3 <- data.frame(col1 = LETTERS[7:9],
col2c= c(2:4),
col3c = NA)
print ("Third DataFrame")
print (df3)
df_merge12 <- merge(df1,df2,by="col1",all.x=TRUE, all.y = TRUE)
df_merge <- merge(df_merge12,df3,by="col1",all.x=TRUE, all.y = TRUE)
print("Merged DataFrame")
print (df_merge)
Producción:
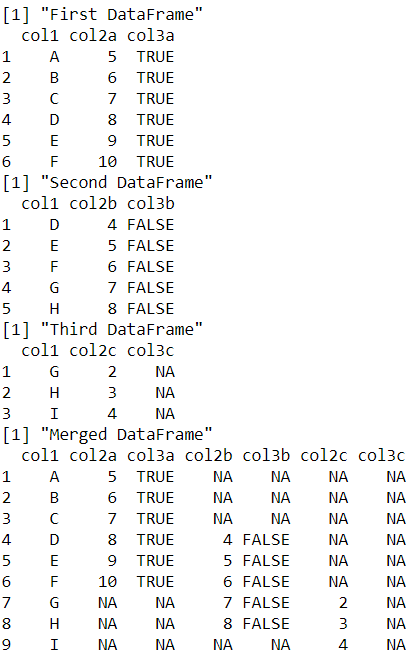
Publicación traducida automáticamente
Artículo escrito por mallikagupta90 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA