Por lo general, queremos concatenar dos o más marcos de datos cuando trabajamos con algunos datos. Entonces, cuando concatenamos estos marcos de datos, necesitamos proporcionar una columna de identificador para identificar los marcos de datos concatenados. En este artículo, veremos con la ayuda de ejemplos de cómo podemos hacer esto.
Ejemplo 1:
Para agregar una columna de identificador, debemos especificar los identificadores como una lista para el argumento «claves» en la función concat(), que crea un nuevo marco de datos de múltiples índices con dos marcos de datos concatenados. Ahora usaremos reset_index para convertir el marco de datos de múltiples índices en un marco de datos de pandas normal.
Python3
import pandas as pd
import numpy as np
dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'],
'Maths':[87, 91, 97, 95],
'Science':[83, 99, 84, 76]
}
df1 = pd.DataFrame(dict)
dict = {'Name':['Amy', 'Maddy'],
'Maths':[89, 90],
'Science':[93, 81]
}
df2 = pd.DataFrame(dict)
# Concatenating two dataframes
df = pd.concat([df1,df2],keys=['t1', 't2'])
display(df)
df = pd.concat([df1,df2], keys=['t1', 't2']).reset_index()
display(df)
Producción:
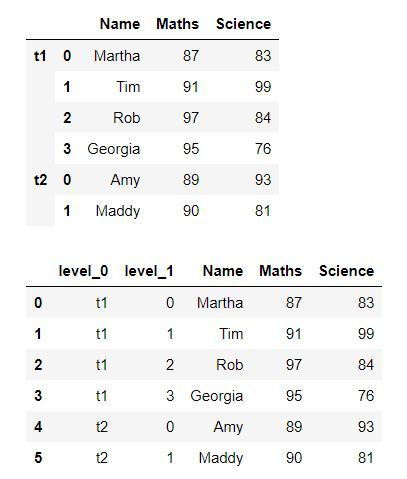
En la salida, podemos ver una columna con los identificadores de cada marco de datos donde «t1» representa el primer marco de datos y «t2» representa el segundo marco de datos.
Ejemplo 2:
Podemos hacer esto de manera similar para cualquier número de marcos de datos. En este ejemplo, combinaremos tres marcos de datos.
Python3
import pandas as pd
import numpy as np
dict = {'Name': ['Martha', 'Tim', 'Rob', 'Georgia'],
'Maths': [87, 91, 97, 95],
'Science': [83, 99, 84, 76]
}
df1 = pd.DataFrame(dict)
dict = {'Name': ['Amy', 'Maddy'],
'Maths': [89, 90],
'Science': [93, 81]
}
df2 = pd.DataFrame(dict)
dict = {'Name': ['Rob', 'Rick', 'Anish'],
'Maths': [89, 90, 87],
'Science': [93, 81, 90]
}
df3 = pd.DataFrame(dict)
# Concatenating Dataframes
df = pd.concat([df1, df2, df3],
keys=['t1', 't2', 't3'])
display(df)
df = pd.concat([df1, df2, df3],
keys=['t1', 't2', 't3']).reset_index()
display(df)
Producción:
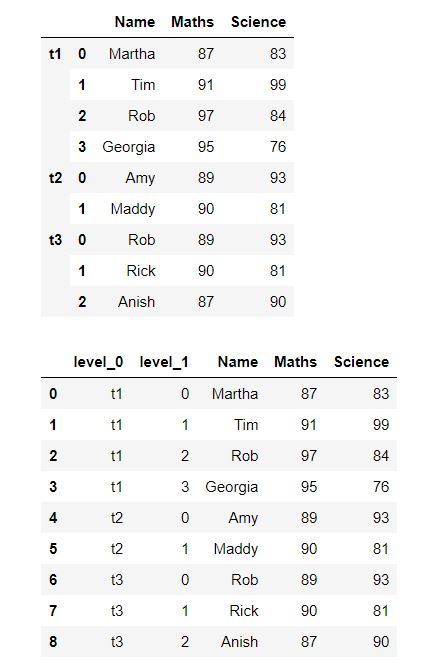
En la salida, podemos ver una columna con los identificadores de cada marco de datos donde «t1», «t2» y «t3» representan el primer, segundo y tercer marco de datos respectivamente.
Publicación traducida automáticamente
Artículo escrito por parasmadan15 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA