En este artículo, aprenderemos cómo agregar estadísticas de resumen a nivel de grupo como una nueva columna en DataFrame Pandas. Esto se puede hacer utilizando el concepto de media estadística, moda, etc. Esto requiere los siguientes pasos:
- Seleccione un marco de datos
- Formar datos estadísticos a partir de una columna o un grupo de columnas
- Almacenar datos como una serie
- Agregue la serie en el marco de datos como una columna.
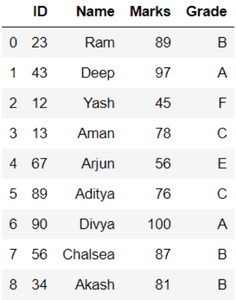
Aquí, tomamos un marco de datos. El marco de datos consiste en la identificación del estudiante, el nombre, las calificaciones y las calificaciones. Vamos a crear el marco de datos
Python3
# importing packages
import pandas as pd
# dictionary of data
dct = {'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep',
2: 'Yash', 3: 'Aman',
4: 'Arjun', 5: 'Aditya',
6: 'Divya', 7: 'Chalsea',
8: 'Akash'},
'Marks': {0: 89, 1: 97, 2: 45, 3: 78,
4: 56, 5: 76, 6: 100, 7: 87,
8: 81},
'Grade': {0: 'B', 1: 'A', 2: 'F', 3: 'C',
4: 'E', 5: 'C', 6: 'A', 7: 'B',
8: 'B'}
}
# create dataframe
df = pd.DataFrame(dct)
# view dataframe
df
Producción:
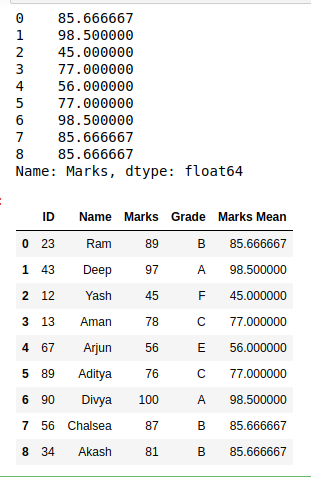
Ahora, encontraremos el resumen de estadísticas a nivel de grupo utilizando el enfoque anterior.
Python3
# make a series
new_column = df.groupby('Grade').Marks.transform('mean')
# view new series
print(new_column)
# add column in dataframe
df["Marks Mean"] = df.groupby('Grade').Marks.transform('mean')
# view modified dataframe
print(df)
Producción:
Publicación traducida automáticamente
Artículo escrito por deepanshu_rustagi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA