En este artículo, veremos cómo agregar una nueva fila de valores a un marco de datos existente. Esto se puede usar cuando queremos insertar una nueva entrada en nuestros datos que podríamos haber pasado por alto antes. Hay diferentes métodos para lograr esto. Ahora veamos con la ayuda de ejemplos cómo podemos hacer esto
Ejemplo 1:
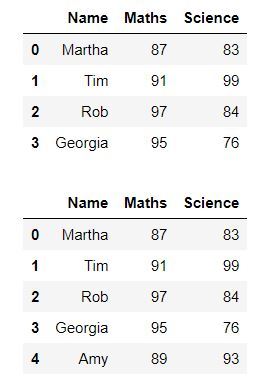
Podemos agregar una sola fila usando DataFrame.loc . Podemos agregar la fila al final de nuestro marco de datos. Podemos obtener el número de filas usando len(DataFrame.index) para determinar la posición en la que necesitamos agregar la nueva fila.
from IPython.display import display, HTML
import pandas as pd
from numpy.random import randint
dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'],
'Maths':[87, 91, 97, 95],
'Science':[83, 99, 84, 76]
}
df = pd.DataFrame(dict)
display(df)
df.loc[len(df.index)] = ['Amy', 89, 93]
display(df)
Producción:
Ejemplo 2:
También podemos agregar una nueva fila usando la función DataFrame.append()
from IPython.display import display, HTML
import pandas as pd
import numpy as np
dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'],
'Maths':[87, 91, 97, 95],
'Science':[83, 99, 84, 76]
}
df = pd.DataFrame(dict)
display(df)
df2 = {'Name': 'Amy', 'Maths': 89, 'Science': 93}
df = df.append(df2, ignore_index = True)
display(df)
Producción:
Ejemplo 3:
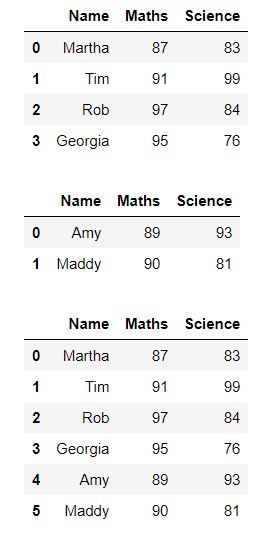
También podemos agregar varias filas usando pandas.concat() al crear un nuevo marco de datos de todas las filas que necesitamos agregar y luego agregar este marco de datos al marco de datos original.
from IPython.display import display, HTML
import pandas as pd
import numpy as np
dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'],
'Maths':[87, 91, 97, 95],
'Science':[83, 99, 84, 76]
}
df1 = pd.DataFrame(dict)
display(df1)
dict = {'Name':['Amy', 'Maddy'],
'Maths':[89, 90],
'Science':[93, 81]
}
df2 = pd.DataFrame(dict)
display(df2)
df3 = pd.concat([df1, df2], ignore_index = True)
df3.reset_index()
display(df3)
Producción:
Publicación traducida automáticamente
Artículo escrito por parasmadan15 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA