En este artículo, discutiremos cómo agregar una nueva columna a PySpark Dataframe.
Cree el primer marco de datos para la demostración:
Aquí, crearemos el marco de datos de muestra que usaremos más adelante para demostrar el propósito del enfoque.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
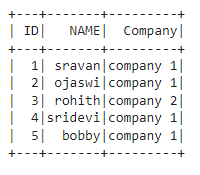
dataframe.show()
Producción:
Método 1: agregar una nueva columna con valor constante
En este enfoque para agregar una nueva columna con valores constantes, el usuario debe llamar al parámetro de función lit() de la función withColumn() y pasar los parámetros requeridos a estas funciones. Aquí, lit() está disponible en pyspark.sql. Módulo de funciones.
Sintaxis :
dataframe.withColumn("column_name", lit(value))
dónde,
- dataframe es el marco de datos de entrada de pyspark
- column_name es la nueva columna que se agregará
- valor es el valor constante que se asignará a esta columna
Ejemplo:
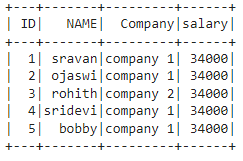
En este ejemplo, agregamos una columna llamada salario con un valor de 34000 al marco de datos anterior usando la función withColumn() con la función lit() como su parámetro en el lenguaje de programación python.
Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Add a column named salary with value as 34000
dataframe.withColumn("salary", lit(34000)).show()
Producción:
Método 2: Agregar columna basada en otra columna de DataFrame
Bajo este enfoque, el usuario puede agregar una nueva columna basada en una columna existente en el marco de datos dado.
Ejemplo 1: Uso del método withColumn()
Aquí, en este ejemplo, el usuario debe especificar la columna existente utilizando la función withColumn() con los parámetros requeridos pasados en el lenguaje de programación python.
Sintaxis :
dataframe.withColumn("column_name", dataframe.existing_column)
dónde,
- dataframe es el dataframe de entrada
- column_name es la nueva columna
- columna_existente es la columna que existe
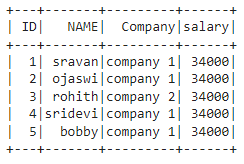
En este ejemplo, estamos agregando una columna llamada salario de la columna ID con una multiplicación de 2300 usando el método withColumn() en el lenguaje python,
Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Add a column named salary from ID column with multiply of 2300
dataframe.withColumn("salary", dataframe.ID*2300).show()
Producción:

Ejemplo 2: Uso de concat_ws()
En este ejemplo, el usuario debe concatenar las dos columnas existentes y convertirlas en una nueva columna importando este método desde el módulo pyspark.sql.functions.
Sintaxis :
dataframe.withColumn(“nombre_columna”, concat_ws(“Separador”,”columna_existente1″,’columna_existente2′))
dónde,
- dataframe es el dataframe de entrada
- column_name es el nuevo nombre de columna
- columna_existente1 y columna_existente2 son las dos columnas que se agregarán con Separator para hacer valores a la nueva columna
- El separador es como el operador entre valores con dos columnas
Ejemplo:
En este ejemplo, agregamos una columna llamada Detalles de las columnas Nombre y Compañía separadas por «-» en el lenguaje python.
Python3
# importing module
import pyspark
# import concat_ws function
from pyspark.sql.functions import concat_ws
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Add a column named Details from Name and Company columns separated by -
dataframe.withColumn("Details", concat_ws("-", "NAME", 'Company')).show()
Producción:

Método 3: Agregar columna cuando no existe en DataFrame
En este método, el usuario puede agregar una columna cuando no existe agregando una columna con la función lit() y verificando si usa la condición.
Sintaxis:
if 'column_name' not in dataframe.columns:
dataframe.withColumn("column_name",lit(value))
dónde,
- marco de datos. las columnas se utilizan para obtener los nombres de las columnas
Ejemplo:
En este ejemplo, agregamos una columna del salario a 34000 usando la condición if con withColumn() y la función lit().
Python3
# importing module
import pyspark
# import concat_ws and lit function
from pyspark.sql.functions import concat_ws, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# add salary column by checking its existence
if 'salary' not in dataframe.columns:
dataframe.withColumn("salary", lit(34000)).show()
Producción:
Método 4: Agregar columna a DataFrame usando select()
En este método, para agregar una columna a un marco de datos, el usuario debe llamar a la función select() para agregar una columna con la función lit() y el método select(). También mostrará las columnas seleccionadas.
Sintaxis :
dataframe.select(lit(value).alias("column_name"))
dónde,
- dataframe es el dataframe de entrada
- column_name es la nueva columna
Ejemplo:
En este ejemplo, agregamos una columna de salario con un valor constante de 34000 utilizando la función select() con la función lit() como parámetro.
Python3
# importing module
import pyspark
# import concat_ws and lit function
from pyspark.sql.functions import concat_ws, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# add salary column with constant value - 34000
dataframe.select(lit(34000).alias("salary")).show()
Producción:

Método 5: Agregar columna a DataFrame usando SQL Expression
En este método, el usuario tiene que usar una expresión SQL con una función SQL para agregar una columna. Antes de eso, tenemos que crear una vista temporal, desde esa vista, tenemos que agregar y seleccionar columnas.
Sintaxis :
dataframe.createOrReplaceTempView("name")
spark.sql("select 'value' as column_name from view")
dónde,
- dataframe es el dataframe de entrada
- name es el nombre de la vista temporal
- La función sql tomará la expresión SQL como entrada para agregar una columna
- column_name es el nuevo nombre de columna
- el valor es el valor de la columna
Ejemplo:
Agregue una nueva columna llamada salario con valor 34000
Python3
# importing module
import pyspark
# import concat_ws and lit function
from pyspark.sql.functions import concat_ws, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# create view
dataframe.createOrReplaceTempView("view")
# add new column named salary with 34000 value
spark.sql("select '34000' as salary from view").show()
Producción:
Método 6: agregar valor de columna según la condición
Bajo este método, el usuario necesita usar la función when junto con el método withcolumn() usado para verificar la condición y agregar los valores de columna basados en los valores de columna existentes. Entonces, tenemos que importar when() desde pyspark.sql.functions para agregar una columna específica según la condición dada.
Sintaxis :
dataframe.withColumn(“nombre_columna”,
when((dataframe.column_name condition1), lit(“value1”)).
when((dataframe.column_name condition2), lit(“value2”)).
———————
———————
when((dataframe.column_name conditionn), lit(“value3”)).
.de lo contrario(lit(“valor”)) )
dónde,
- column_name es el nuevo nombre de columna
- condition1 es la condición para verificar y asignar value1 usando lit() hasta when
- de lo contrario, es la palabra clave utilizada para verificar cuando no se cumple ninguna condición.
Ejemplo:
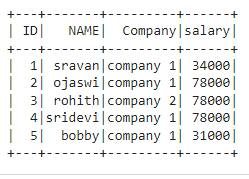
En este ejemplo, agregamos una nueva columna llamada salario y agregamos el valor 34000 cuando el nombre es sravan y agregamos el valor 31000 cuando el nombre es ojsawi, o bobby agrega 78000 usando las funciones when() y withColumn().
Python3
# importing module
import pyspark
# import when and lit function
from pyspark.sql.functions import when, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# add a new column named salary
# add value 34000 when name is sravan
# add value 31000 when name is ojsawi or bobby
# otherwise add 78000
dataframe.withColumn("salary",
when((dataframe.NAME == "sravan"), lit("34000")).
when((dataframe.NAME == "ojsawi") | (
dataframe.NAME == "bobby"), lit("31000"))
.otherwise(lit("78000"))).show()
Producción:
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA