En este artículo, discutiremos cómo aplanar multiIndex en pandas.
Aplane todos los niveles de MultiIndex:
En este método, vamos a aplanar todos los niveles del marco de datos usando la función reset_index() .
Sintaxis :
dataframe.reset_index(inplace=True)
Nota: Dataframe es el dataframe de entrada, tenemos que crear el dataframe MultiIndex.
Sintaxis :
MultiIndex.from_tuples([(tuple1),.......,(tuple n),names=[column_names])
Argumentos:
- las tuplas son los valores
- los nombres de las columnas son los nombres de las columnas en cada valor de tupla
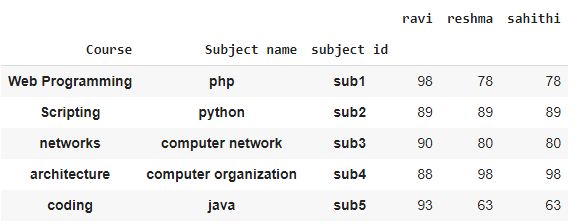
Ejemplo :
En este ejemplo, crearemos un dataframe junto con multiIndex y lo mostraremos en el lenguaje de programación python.
Python3
import pandas as pd
# create DataFrame muktiindexex
data = pd.MultiIndex.from_tuples([('Web Programming', 'php', 'sub1'),
('Scripting', 'python', 'sub2'),
('networks', 'computer network', 'sub3'),
('architecture', 'computer organization', 'sub4'),
('coding', 'java', 'sub5')],
names=['Course', 'Subject name', 'subject id'])
# create dataframe with student marks
data = pd.DataFrame({'ravi': [98, 89, 90, 88, 93],
'reshma': [78, 89, 80, 98, 63],
'sahithi': [78, 89, 80, 98, 63]},
index=data)
# display
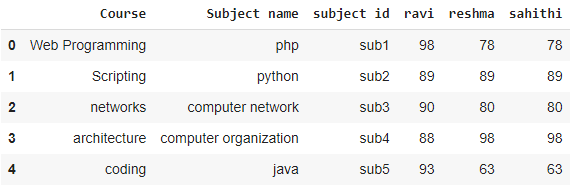
data
Producción:
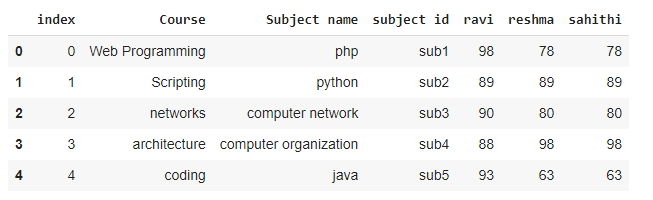
Ahora, aplanaremos el índice de todos los niveles:
Python3
import pandas as pd
# create DataFrame muktiindexex
data = pd.MultiIndex.from_tuples([('Web Programming', 'php', 'sub1'),
('Scripting', 'python', 'sub2'),
('networks', 'computer network', 'sub3'),
('architecture', 'computer organization', 'sub4'),
('coding', 'java', 'sub5')],
names=['Course', 'Subject name', 'subject id'])
# create dataframe with student marks
data = pd.DataFrame({'ravi': [98, 89, 90, 88, 93],
'reshma': [78, 89, 80, 98, 63],
'sahithi': [78, 89, 80, 98, 63]},
index=data)
# flatten the index of all levels
data.reset_index(inplace=True)
# display
data
Producción:
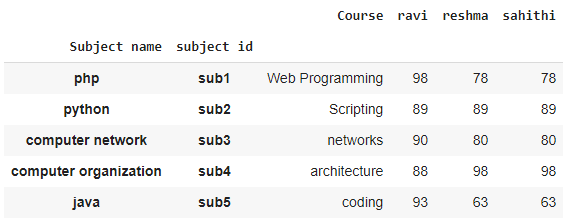
Aplanar niveles específicos de MultiIndex
Al usar niveles específicos podemos obtener usando la siguiente sintaxis:
dataframe.reset_index(inplace=True,level=['level_name'])
dónde
- dataframe es el dataframe de entrada
- level_name es el nombre del nivel multiíndice
Ejemplo:
En este ejemplo, crearemos un dataframe y aplanaremos niveles específicos de multiIndex y lo mostraremos en el lenguaje de programación python.
Python3
import pandas as pd
# create DataFrame muktiindexex
data = pd.MultiIndex.from_tuples([('Web Programming', 'php', 'sub1'),
('Scripting', 'python', 'sub2'),
('networks', 'computer network', 'sub3'),
('architecture', 'computer organization', 'sub4'),
('coding', 'java', 'sub5')],
names=['Course', 'Subject name', 'subject id'])
# create dataframe with student marks
data = pd.DataFrame({'ravi': [98, 89, 90, 88, 93],
'reshma': [78, 89, 80, 98, 63],
'sahithi': [78, 89, 80, 98, 63]},
index=data)
# flatten the index of level with course column
data.reset_index(inplace=True, level=['Course'])
# display
data
Producción:
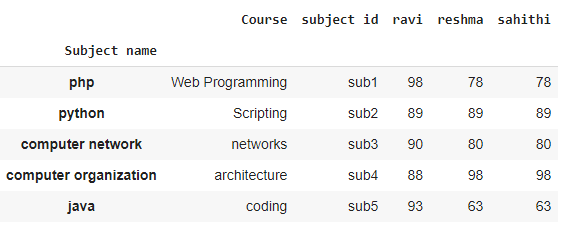
También podemos especificar múltiples niveles;
Python3
import pandas as pd
# create DataFrame muktiindexex
data = pd.MultiIndex.from_tuples([('Web Programming', 'php', 'sub1'),
('Scripting', 'python', 'sub2'),
('networks', 'computer network', 'sub3'),
('architecture', 'computer organization', 'sub4'),
('coding', 'java', 'sub5')],
names=['Course', 'Subject name', 'subject id'])
# create dataframe with student marks
data = pd.DataFrame({'ravi': [98, 89, 90, 88, 93],
'reshma': [78, 89, 80, 98, 63],
'sahithi': [78, 89, 80, 98, 63]},
index=data)
# flatten the index of level with course
# and subject id columns
data.reset_index(inplace=True, level=['Course', 'subject id'])
# display
data
Producción:
Usando el método to_records()
Este es un método de módulo pandas que se utiliza para convertir marcos de datos multiíndice en cada registro y visualización.
Sintaxis :
dataframe.to_records()
Ejemplo:
Python3
import pandas as pd
# create DataFrame muktiindexex
data = pd.MultiIndex.from_tuples([('Web Programming', 'php', 'sub1'),
('Scripting', 'python', 'sub2'),
('networks', 'computer network', 'sub3'),
('architecture', 'computer organization', 'sub4'),
('coding', 'java', 'sub5')],
names=['Course', 'Subject name', 'subject id'])
# create dataframe with student marks
data = pd.DataFrame({'ravi': [98, 89, 90, 88, 93],
'reshma': [78, 89, 80, 98, 63],
'sahithi': [78, 89, 80, 98, 63]},
index=data)
pd.DataFrame(data.to_records())
Producción:
Publicación traducida automáticamente
Artículo escrito por bhanusivanagulug y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA