En este artículo, vamos a ver el aplanamiento de un índice jerárquico en las columnas de Pandas DataFrame. El índice jerárquico generalmente ocurre como resultado de funciones de agregación groupby. La función agregada utilizada aparecerá en el índice jerárquico del marco de datos resultante.
Método 1: Usar la función reset_index()
Pandas proporciona una función llamada reset_index() para aplanar el índice jerárquico creado debido a la función de agregación groupby.
Sintaxis: pandas.DataFrame.reset_index(level, drop, inplace)
Parámetros:
- nivel: elimina solo los niveles especificados del índice
- drop: restablece el índice al índice entero predeterminado
- inplace: modifica el objeto del marco de datos de forma permanente sin crear una copia.
Ejemplo:
En este ejemplo, usamos la función pandas groupby para agrupar los datos de ventas de automóviles por trimestres y la función pandas reset_index() para aplanar las columnas indexadas jerárquicas del marco de datos agrupado.
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
# group by cars based on the sum
# of sales on quarter 1 and 2
grouped_data = data.groupby(by="cars").agg("sum")
print(grouped_data)
# use reset_index to flattened
# the hierarchical dataframe.
flat_data = grouped_data.reset_index()
print(flat_data)
Producción:

Método 2: Usar la función as_index()
Pandas proporciona una función llamada as_index() que se especifica mediante un valor booleano. Las funciones as_index() agrupan el marco de datos por la función agregada especificada y si el valor de as_index() es Falso, el marco de datos resultante se aplana.
Sintaxis: pandas.DataFrame.groupby(by, level, axis, as_index)
Parámetros:
- by: especifica las columnas en las que se debe realizar la operación groupby
- nivel: especifica el índice en el que se deben agrupar las columnas
- eje: especifica si dividir por filas (0) o columnas (1)
- as_index: devuelve un objeto con etiquetas de grupo como índice, para la salida agregada.
Ejemplo:
En este ejemplo, estamos usando la función pandas groupby para agrupar los datos de ventas de automóviles por trimestres y mencionamos el parámetro as_index como Falso y especificamos el parámetro as_index como falso para garantizar que el índice jerárquico del marco de datos agrupado se aplana.
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
# group by cars based on the
# sum of sales on quarter 1 and 2
# and mention as_index is False
grouped_data = data.groupby(by="cars", as_index=False).agg("sum")
# display
print(grouped_data)
Producción:
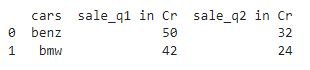
Método 3: aplanar el índice jerárquico en el marco de datos de pandas usando groupby
Cada vez que usamos la función groupby en una sola columna con múltiples funciones de agregación, obtenemos múltiples índices jerárquicos basados en el tipo de agregación. En tales casos, el índice jerárquico debe aplanarse en ambos niveles.
Sintaxis: pandas.DataFrame.groupby(by=Ninguno, eje=0, nivel=Ninguno)
Explicación:
- by: función de mapeo que determina los grupos en la función groupby
- eje – 0 – se divide a lo largo de las filas y 1 – se divide a lo largo de las columnas.
- nivel: si el eje tiene varios índices, se agrupa en un nivel específico. (En t)
Sintaxis: pandas.DataFrame.agg(func=Ninguno, eje=0)
Explicación:
- func: especifica la función que se utilizará como función de agregación. (mín., máx., suma, etc.)
- eje – 0 – función aplicada a cada columna y 1- aplicada a cada fila.
Acercarse:
- Importe el paquete pandas de python.
- Cree un marco de datos de muestra que muestre las ventas de automóviles en dos trimestres q1 y q2 como se muestra.
- Ahora use la función pandas groupby para agrupar según la suma y el máximo de ventas en el trimestre 1 y la suma y el mínimo de ventas en el 2.
- El marco de datos agrupado tiene columnas indexadas múltiples almacenadas en una lista de tuplas. Use un bucle for para iterar a través de la lista de tuplas y unirlas como una sola string.
- Agregue las strings unidas en la lista flat_cols. </li> <li> Ahora asigne la lista flat_cols a los nombres de columna de las columnas de marco de datos agrupados con múltiples índices.
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
# group by cars based on the sum and max of sales on quarter 1
# and sum and min of sales 2 and mention as_index is False
grouped_data = data.groupby(by="cars").agg({"sale_q1 in Cr": [sum, max],
'sale_q2 in Cr': [sum, min]})
# create an empty list to save the
# names of the flattened columns
flat_cols = []
# the multiindex columns of two
# levels would be stored as tuples
# iterate through this tuples and
# join them as single string
for i in grouped_data.columns:
flat_cols.append(i[0]+'_'+i[1])
# now assign the list of flattened
# columns to the grouped columns.
grouped_data.columns = flat_cols
# print the grouped data
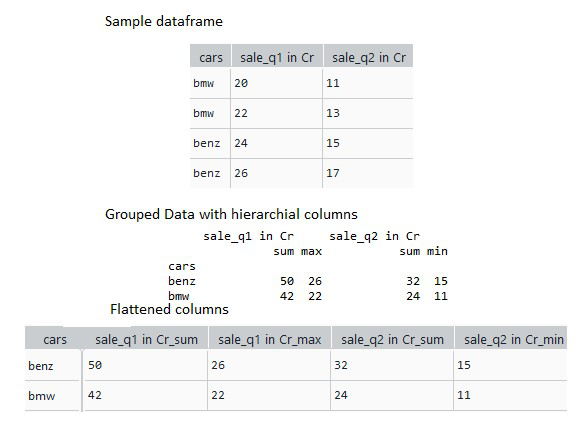
print(grouped_data)
Producción:
Método 4: aplanar el índice jerárquico usando la función to_records()
En este ejemplo, usamos la función to_records() del marco de datos pandas que convierte todas las filas en el marco de datos como una array de tuplas . Esta array de tuplas luego se pasa a la función pandas.DataFrame para convertir el índice jerárquico en columnas planas.
Sintaxis: pandas.DataFrame.to_records(index=Verdadero, column_dtypes=Ninguno)
Explicación:
- índice: crea un índice en la array resultante
- column_dtypes: establece las columnas en el tipo de datos especificado.
Código:
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
# group by cars based on the sum
# and max of sales on quarter 1
# and sum and min of sales 2 and mention
# as_index is False
grouped_data = data.groupby(by="cars").agg({"sale_q1 in Cr": [sum, max],
'sale_q2 in Cr': [sum, min]})
# use to_records function on grouped data
# and pass this to the Dataframe function
flattened_data = pd.DataFrame(grouped_data.to_records())
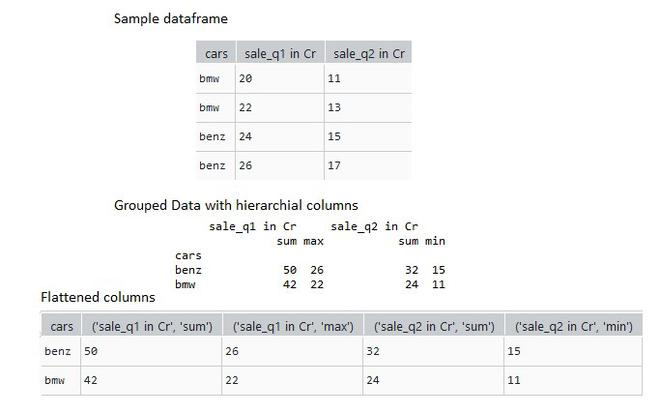
print(flattened_data)
Producción:
Método 5: aplanar columnas jerárquicas usando join() y rstrip()
En este ejemplo, usamos las funciones join() y rstrip() para aplanar las columnas. Por lo general, cuando agrupamos un marco de datos como columnas indexadas jerárquicas, las columnas en varios niveles se almacenan como una array de elementos de tuplas. Aquí, iteramos a través de estas tuplas uniendo el nombre de la columna y el nombre del índice de cada tupla y almacenando el nombre de las columnas aplanadas resultantes en una lista. Posteriormente, esta lista almacenada de columnas aplanadas se asigna al marco de datos agrupado.
Sintaxis: str.join(iterable)
Explicación: devuelve una string concatenada, si es iterable; de lo contrario, devuelve un error de tipo.
Sintaxis: str.rstrip([caracteres])
Explicación: Devuelve una string dividiendo los espacios finales sobrantes (más a la derecha) de la string.
Código:
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
# group by cars based on the sum
# and max of sales on quarter 1
# and sum and min of sales 2 and
# mention as_index is False
grouped_data = data.groupby(by="cars").agg({"sale_q1 in Cr": [sum, max],
'sale_q2 in Cr': [sum, min]})
# use join() and rstrip() function to
# flatten the hierarchical columns
grouped_data.columns = ['_'.join(i).rstrip('_')
for i in grouped_data.columns.values]
print(grouped_data)
Producción:
Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA