En este artículo, veamos cómo aplicar funciones en un grupo en un Dataframe de Pandas. Los pasos a seguir para realizar esta tarea son:
- Importe las bibliotecas necesarias .
- Configure los datos como Pandas DataFrame .
- Use la función de aplicación para encontrar diferentes medidas estadísticas como Media móvil, Promedio, Suma, Máximo y Mínimo. Puede usar la función lambda para esto.
A continuación se muestra la implementación-
Vamos a crear el marco de datos.
Python3
#import libraries
import pandas as pd
# set up the data
data_dict = {"Student House": ["Lavender", "Lavender", "Lavender",
"Lavender", "Daisy", "Daisy",
"Daisy", "Daisy", "Daffodils",
"Daffodils", "Daffodils", "Daffodils"],
"Points": [10, 4, 6, 7, 3, 8, 9, 10, 4, 5, 6, 7]}
data_df = pd.DataFrame(data_dict)
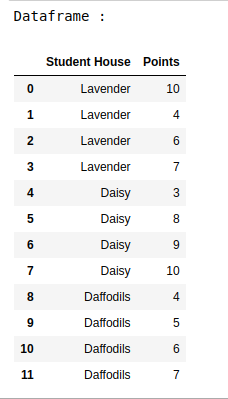
print("Dataframe : ")
data_df
Producción:
Ejemplo 1:
Python3
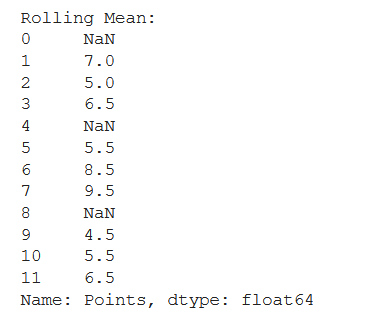
# finding rolling mean
rolling_mean = data_df.groupby("Student House")["Points"].apply(
lambda x: x.rolling(center=False, window=2).mean())
print("Rolling Mean:")
print(rolling_mean)
Producción:
Ejemplo 2:
Python3
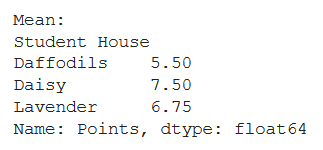
# finding mean
mean = data_df.groupby("Student House")["Points"].apply(
lambda x: x.mean())
print("Mean:")
print(mean)
Producción:
Ejemplo 3:
Python3
# finding sum
sum = data_df.groupby("Student House")["Points"].apply(
lambda x: x.sum())
print("Sum:")
print(sum)
Producción:

Publicación traducida automáticamente
Artículo escrito por devanshigupta1304 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA