Un promedio ponderado es un cálculo que considera el valor relativo de los números enteros en una recopilación de datos. Cada valor en el conjunto de datos se escala por un peso predefinido antes de que se complete el cálculo final cuando se calcula un promedio ponderado.
Sintaxis:
def weighted_average(dataframe, value, weight):
val = dataframe[value]
wt = dataframe[weight]
return (val * wt).sum() / wt.sum()
Devolverá el promedio ponderado del artículo en valor. En el numerador, multiplicamos cada valor con el peso correspondiente asociado y los sumamos todos. En el denominador se suman todos los pesos.
Acercarse
- Tomamos un marco de datos o hacemos nuestro propio marco de datos.
- Defina una función para calcular el promedio ponderado por la fórmula mencionada anteriormente.
- Necesitamos tener al menos tres elementos en el marco de datos, es decir, índice (que puede ser el nombre del elemento, la fecha o cualquier variable similar), el valor y el peso.
- Haremos una llamada de función pasando estos tres valores.
Ejemplo :
Veamos un ejemplo para calcular el promedio ponderado del valor agrupado por item_name.
Supongamos que hay tres tiendas y cada tienda contiene tres artículos, es decir, chocolates, helados y galletas. Tenemos el peso de cada uno de los artículos y el precio de cada uno de los artículos en las tres tiendas. Ahora necesitamos encontrar el promedio ponderado de cada elemento.
Python3
import pandas as pd
def weighted_average(dataframe, value, weight):
val = dataframe[value]
wt = dataframe[weight]
return (val * wt).sum() / wt.sum()
# creating a dataframe to represent different
# items and their corresponding weight and value
dataframe = pd.DataFrame({'item_name': ['Chocolate', 'Chocolate',
'Chocolate', 'Biscuit',
'Biscuit', 'Biscuit',
'IceCream', 'IceCream',
'IceCream'],
'value': [90, 50, 86, 87, 42, 48,
68, 92, 102],
'weight': [4, 2, 3, 5, 6, 5, 3, 7,
5]})
# Weighted average of value grouped by item name
dataframe.groupby('item_name').apply(weighted_average,
'value', 'weight')
Salida :
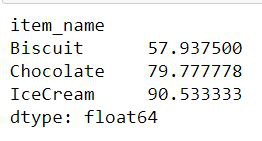
Usando groupby()
Aquí vamos a agrupar los elementos usando la función groupby() y calcularemos los pesos agrupando estos elementos junto con la función de suma. Entonces, al usar este método, solo estamos formando un grupo de elementos similares para obtener la suma
Sintaxis:
def weighted_average_of_group(values, weights, item):
return (values * weights).groupby(item).sum() / weights.groupby(item).sum()
Ejemplo :
Python3
import pandas as pd
def weighted_average_of_group(values, weights, item):
return (values * weights).groupby(item).sum() / weights.groupby(item).sum()
# creating a dataframe to represent different items
# and their corresponding weight and value
dataframe = pd.DataFrame({'item_name': ['Chocolate', 'Chocolate', 'Chocolate',
'Biscuit', 'Biscuit', 'Biscuit',
'IceCream', 'IceCream', 'IceCream'],
'value': [90, 50, 86, 87, 42, 48, 68, 92, 102],
'weight': [4, 2, 3, 5, 6, 5, 3, 7, 5]})
# Finding grouped average of group
weighted_average_of_group(values=dataframe.value,
weights=dataframe.weight, item=dataframe.item_name)
Salida :

Para calcular el promedio ponderado de todo el marco de datos (no de cada grupo, sino como un todo) usaremos la sintaxis que se muestra a continuación:
Sintaxis
def weighted_average_of_whole_dataframe(dataframe, value, weight):
val = dataframe[value]
wt = dataframe[weight]
return (val * wt).sum() / wt.sum()
Ejemplo :
Python3
import pandas as pd
def weighted_average(dataframe, value, weight):
val = dataframe[value]
wt = dataframe[weight]
return (val * wt).sum() / wt.sum()
# creating a dataframe to represent different items
# and their corresponding weight and value
dataframe = pd.DataFrame({'item_name': ['Chocolate', 'Chocolate', 'Chocolate',
'Biscuit', 'Biscuit', 'Biscuit',
'IceCream', 'IceCream', 'IceCream'],
'value': [90, 50, 86, 87, 42, 48, 68, 92, 102],
'weight': [4, 2, 3, 5, 6, 5, 3, 7, 5]})
# Weighted average of whole dataframe as a whole
weighted_average(dataframe, 'value', 'weight')
Producción:
75.075