La estimación puntual es una técnica utilizada para encontrar la estimación o el valor aproximado de los parámetros de la población a partir de una muestra de datos dada de la población. La estimación puntual se calcula para los siguientes dos parámetros de medición:
| Parámetro de medición | Parámetro de población | Punto estimado |
|---|---|---|
| Proporción | π | pags |
| Significar | m | X |
Este artículo se centra en cómo podemos calcular estimaciones puntuales en el lenguaje de programación R.
La estimación puntual de la proporción de la población
La estimación puntual de la proporción de la población se puede calcular utilizando la siguiente fórmula matemática,
Sintaxis: p′ = x / n
Aquí,
- x : Significa el número de éxitos
- n : Significa el tamaño de la muestra.
- p′ es la estimación puntual de la proporción de la población
Ejemplo:
Digamos que queremos estimar la proporción de estudiantes en una clase que están presentes en un día en particular. Los datos de muestra constan de 20 elementos de datos.
R
# define data
data <- c('Present', 'Absent', 'Absent', 'Absent',
'Absent', 'Absent', 'Present', 'Present',
'Absent', 'Present',
'Present', 'Present', 'Present', 'Present',
'Present', 'Present', 'Absent', 'Present',
'Present', 'Present')
# find total sample size
n <- length(data)
# find number who are present
k <- sum(data == 'Present')
# find sample proportion
p <- k/n
# print
print(paste("Sample proportion of students who are present", p))
Producción:
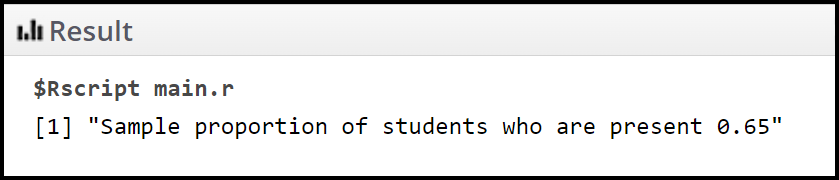
Ejemplo:
Tenga en cuenta que podemos calcular el intervalo de confianza del 95% para la proporción de la población utilizando el siguiente código fuente,
R
# define data
data <- c('Present', 'Absent', 'Absent', 'Absent',
'Absent', 'Absent', 'Present', 'Present',
'Absent', 'Present',
'Present', 'Present', 'Present', 'Present',
'Present', 'Present', 'Absent', 'Present',
'Present', 'Present')
# find total sample size
total <- length(data)
# find number who responded 'Yes'
favourable <- sum(data == 'Present')
# find sample proportion
ans <- favourable/total
# calculate margin of error
margin <- qnorm(0.975)*sqrt(ans*(1-ans)/total)
# calculate lower and upper bounds of
# confidence interval
low <- ans - margin
print(low)
high <- ans + margin
print(high)
Producción:
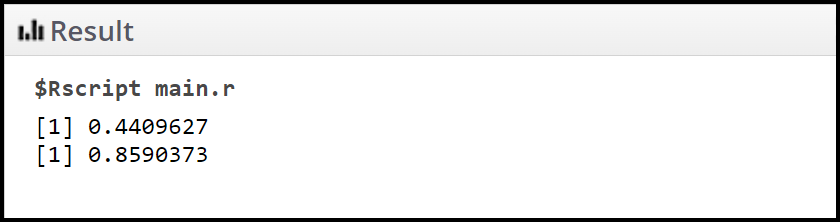
Por lo tanto, el intervalo de confianza del 95 % para la proporción de la población es [0,440, 0,859].
La estimación puntual de la media de una población
La estimación puntual de la media de la población se puede calcular utilizando la función mean() en R. La sintaxis se proporciona a continuación,
Sintaxis: mean(x, trim = 0, na.rm = FALSE, …)
Aquí,
- x: Es el vector de entrada
- trim: se utiliza para eliminar algunas observaciones de ambos extremos del vector ordenado
- na.rm: se utiliza para eliminar los valores faltantes del vector de entrada
Ejemplo:
Digamos que queremos estimar la media poblacional de las alturas de los estudiantes en una clase. Los datos de muestra constan de 20 elementos de datos.
R
#define data
data <- c(170, 180, 165, 170, 165,
175, 160, 162, 156, 159,
160, 167, 168, 174, 180,
167, 169, 180, 190, 195)
#calculate sample mean
ans <- mean(data, na.rm = TRUE)
#print the mean height
print(paste("The sample mean is", ans))
Producción:
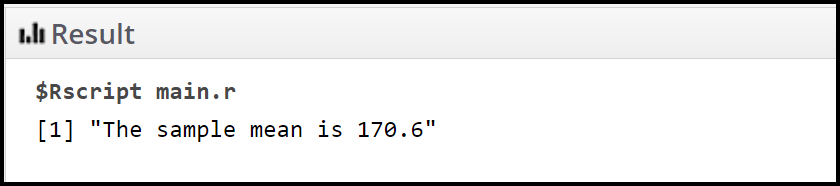
Por lo tanto, la muestra significa que la altura es de 170,6 cm.
Ejemplo:
Tenga en cuenta que podemos calcular el intervalo de confianza del 95% para la media de la población utilizando el siguiente código fuente,
R
# define data data <- c(170, 180, 165, 170, 165, 175, 160, 162, 156, 159, 160, 167, 168, 174, 180, 167, 169, 180, 190, 195) # Total number of students total <- length(data) # Point estimate of mean favourable <- mean(data, na.rm = TRUE) s <- sd(data) # calculate margin of error margin <- qt(0.975,df=total-1)*s/sqrt(total) # calculate lower and upper bounds of # confidence interval low <- favourable - margin print(low) high <- favourable + margin print(high)
Producción:
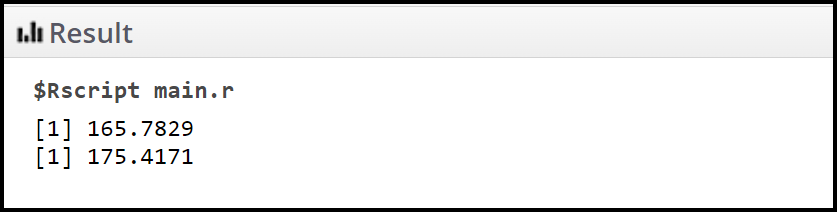
Por lo tanto, el intervalo de confianza del 95 % para la media de la población es [165,782, 175,417].