En este artículo vamos a ver cómo calcular la media por grupo en DataFrame en lenguaje de programación R.
Se puede hacer con dos enfoques:
- Usando la función agregada
- Usando el paquete dplyr
Creación de conjuntos de datos: primero, creamos un conjunto de datos para que luego podamos aplicar los dos enfoques anteriores y encontrar la media por grupo.
R
# GFG dataset name and creation
GFG <- data.frame(
Category = c ("A","B","C","B","C","A","C","A","B"),
Frequency= c(9,5,0,2,7,8,1,3,7)
)
# Prints the dataset
print(GFG)
Entonces, como puede ver, el código anterior es para crear un conjunto de datos llamado «GFG».
También tiene 2 columnas denominadas Categoría y Frecuencia. Entonces, cuando ejecuta el código anterior en un compilador R, se muestra una tabla como salida como se indica a continuación
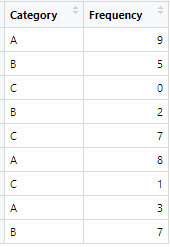
Y después de aplicar esos dos enfoques, necesitamos obtener resultados como:
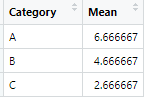
Antes de discutir esos enfoques, primero sepamos cómo obtuvimos los valores de salida:
- En la Tabla 1, tenemos dos columnas denominadas Categoría y Frecuencia.
- En Categoría, tenemos algunas variables repetitivas de A, B y C.
- Valores del grupo A (9,8,3) , valores del grupo B (5,2,7) y valores del grupo C (0,7,1) tomados de la columna Frecuencia .
- Entonces, para encontrar la media tenemos una fórmula
MEDIA = Suma de términos / Número de términos
- Por lo tanto, la media por grupo de cada grupo (A,B,C) sería
Suma:
- A=9+8+3=20
- segundo=5+2+7=14
- C=0+7+1=08
Número de términos:
- A se repite 3 veces
- B se repite 3 veces
- C se repite 3 veces
Media por grupo (A, B, C):
- A(media) = Suma/Número de términos = 20/3 = 6,67
- B(media) = Suma/Número de términos = 14/3 = 4,67
- C(media) = Suma/Número de términos = 8/3 = 2,67
Método 1: Usar la función agregada
Función agregada: divide los datos en subconjuntos, calcula estadísticas de resumen para cada uno y devuelve el resultado en una forma conveniente.
Sintaxis: agregado (x = dataset_Name, by = group_list, FUN = any_function)
# Sintaxis básica de R de la función agregada
Ahora, sumemos nuestros datos usando una función agregada:
R
GFG <- data.frame(
Category = c ("A","B","C","B","C","A","C","A","B"),
Frequency= c(9,5,0,2,7,8,1,3,7)
)
# Specify data column
aggregate(x= GFG$Frequency,
# Specify group indicator
by = list(GFG$Category),
# Specify function (i.e. mean)
FUN = mean)
Producción:

En la función agregada anterior, toma tres parámetros
- Primero está el nombre del conjunto de datos, en nuestro caso es «GFG».
- El segundo es el nombre de la columna cuyos valores necesitamos para hacer diferentes grupos, en nuestro caso es la columna Categoría, y está separada en tres grupos (A, B, C).
- En el tercer parámetro, debemos mencionar qué función (es decir, media, suma, etc.) debemos realizar en un grupo formado (A, B, C)
Método 2: Uso del paquete dplyr
dplyr es un paquete que proporciona un conjunto de herramientas para manipular conjuntos de datos de manera eficiente en R
Métodos en el paquete dplyr:
- mutate() agrega nuevas variables que son funciones de variables existentes
- select() elige variables en función de sus nombres.
- filter() elige casos en función de sus valores.
- summarise() reduce múltiples valores a un solo resumen.
- arreglar() cambia el orden de las filas.
Instale esta biblioteca:
install.packages("dplyr")
Cargue esta biblioteca:
library("dplyr")
Código:
R
# load dplyr library
library("dplyr")
GFG <- data.frame(
Category = c ("A","B","C","B","C","A","C","A","B"),
Frequency= c(9,5,0,2,7,8,1,3,7)
)
# Specify data frame
GFG%>%
# Specify group indicator, column, function
group_by(Category) %>%
summarise_at(vars(Frequency),
list(name = mean))
Producción:
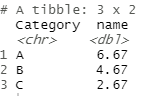
En el código anterior, primero tomamos nuestro conjunto de datos llamado «GFG» . Con el método group_by() formamos grupos en nuestro caso (A, B, C). summarise_at() tiene dos parámetros primero es una columna en la que aplica la operación dada como el segundo parámetro de la misma.
Publicación traducida automáticamente
Artículo escrito por code_blooded7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA