En este artículo, vamos a ver cómo cambiar los nombres de las columnas en el marco de datos pyspark.
Vamos a crear un marco de datos para la demostración:
Python3
# Importing necessary libraries
from pyspark.sql import SparkSession
# Create a spark session
spark = SparkSession.builder.appName('pyspark - example join').getOrCreate()
# Create data in dataframe
data = [(('Ram'), '1991-04-01', 'M', 3000),
(('Mike'), '2000-05-19', 'M', 4000),
(('Rohini'), '1978-09-05', 'M', 4000),
(('Maria'), '1967-12-01', 'F', 4000),
(('Jenis'), '1980-02-17', 'F', 1200)]
# Column names in dataframe
columns = ["Name", "DOB", "Gender", "salary"]
# Create the spark dataframe
df = spark.createDataFrame(data=data,
schema=columns)
# Print the dataframe
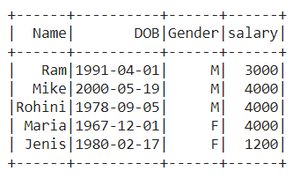
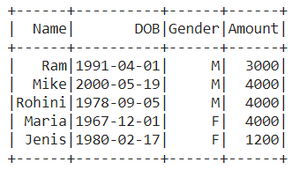
df.show()
Producción :
Método 1: Usando withColumnRenamed()
Usaremos el método withColumnRenamed() para cambiar los nombres de columna del marco de datos pyspark.
Sintaxis: DataFrame.withColumnRenamed(existente, nuevo)
Parámetros
- existingstr: nombre de columna existente del marco de datos para cambiar el nombre.
- newstr: Nuevo nombre de columna.
- Tipo de devolución: devuelve un marco de datos cambiando el nombre de una columna existente.
Ejemplo 1: Cambiar el nombre de la única columna en el marco de datos
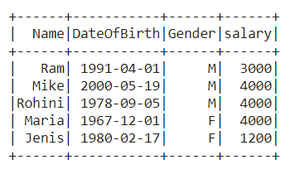
Aquí estamos cambiando el nombre de la columna ‘DOB’ a ‘DateOfBirth’.
Python3
# Rename the column name from DOB to DateOfBirth
# Print the dataframe
df.withColumnRenamed("DOB","DateOfBirth").show()
Producción :
Ejemplo 2: cambio de nombre de varias columnas
Python3
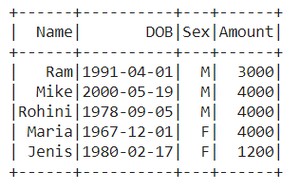
# Rename the column name 'Gender' to 'Sex'
# Then for the returning dataframe
# again rename the 'salary' to 'Amount'
df.withColumnRenamed("Gender","Sex").
withColumnRenamed("salary","Amount").show()
Producción :
Método 2: Usar selectExpr()
Cambiar el nombre de las columnas usando el método selectExpr()
Sintaxis: DataFrame.selectExpr(expr)
Parámetros:
expr: es una expresión SQL.
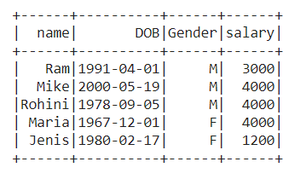
Aquí estamos renombrando Nombre como un nombre.
Python3
# Select the 'Name' as 'name'
# Select remaining with their original name
data = df.selectExpr("Name as name","DOB","Gender","salary")
# Print the dataframe
data.show()
Producción :
Método 3: Usando el método select()
Sintaxis: DataFrame.select(columnas)
Parámetros:
cols: Lista de nombres de columnas como strings.
Tipo de devolución: selecciona las columnas en el marco de datos y devuelve un nuevo marco de datos.
Aquí cambiamos el nombre de la columna ‘salario’ a ‘Cantidad’
Python3
# Import col method from pyspark.sql.functions
from pyspark.sql.functions import col
# Select the 'salary' as 'Amount' using aliasing
# Select remaining with their original name
data = df.select(col("Name"),col("DOB"),
col("Gender"),
col("salary").alias('Amount'))
# Print the dataframe
data.show()
Producción :
Método 4: Usar toDF()
Esta función devuelve un nuevo DataFrame con nuevos nombres de columna especificados.
Sintaxis: toDF(*col)
Donde, col es un nuevo nombre de columna
En este ejemplo, crearemos una lista ordenada de nuevos nombres de columna y la pasaremos a la función toDF
Python3
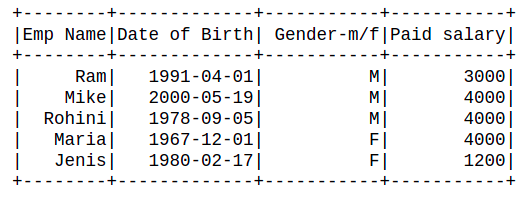
Data_list = ["Emp Name","Date of Birth", " Gender-m/f","Paid salary"] new_df = df.toDF(*Data_list) new_df.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por ManikantaBandla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA