Pandas en una herramienta de análisis de datos de código abierto flexible y fácil de usar construida sobre python, lo que facilita la importación y visualización de datos de diferentes formatos como . csv , . tsv , . txt e incluso archivos .db .
Para los siguientes ejemplos, solo consideraremos . csv , pero el proceso es similar para otros tipos de archivos. El método utilizado para leer archivos CSV es read_csv()
Parámetros:
filepath_or_bufferstr : cualquier ruta de string válida es aceptable. La string podría ser una URL. Los esquemas de URL válidos incluyen http, ftp, s3, gs y archivo. Para las URL de archivo, se espera un host. Un archivo local podría ser: file://localhost/path/to/table.csv.
iteratorbool : por defecto Falso Devuelve el objeto TextFileReader para la iteración o para obtener fragmentos con get_chunk().
chunksize : int, opcional Retorna el objeto TextFileReader para la iteración. Consulte los documentos de IO Tools para obtener más información sobre iterator y chunksize.
El método read_csv() tiene muchos parámetros, pero el que nos interesa es chunksize . Técnicamente, el número de filas leídas a la vez en un archivo por pandas se conoce como tamaño de fragmento . Supongamos que si el tamaño de fragmento es 100, los pandas cargarán las primeras 100 filas. El objeto devuelto no es un marco de datos sino un TextFileReader que debe iterarse para obtener los datos.
Ejemplo 1: cargando una gran cantidad de datos normalmente.
En el siguiente programa vamos a utilizar el conjunto de datos de clasificación de toxicidad que tiene más de 10000 filas. Esto no es mucho, pero será suficiente para nuestro ejemplo.
Python3
import pandas as pd
from pprint import pprint
df = pf.read_csv('train/train.csv')
df.columns
Producción:

Primero, carguemos el conjunto de datos y verifiquemos el número diferente de columnas. Este conjunto de datos tiene 8 columnas.
Obtengamos más información sobre el tipo de datos y la cantidad de filas en el conjunto de datos.
Python3
df.info()
Producción:
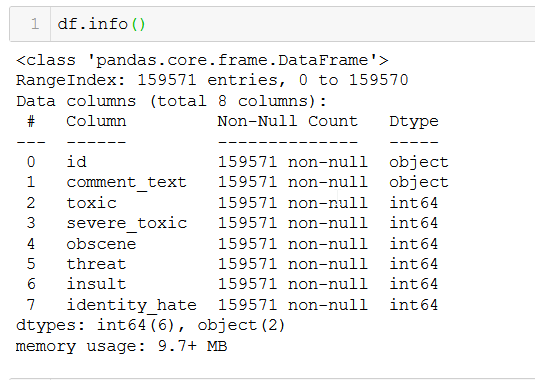
Tenemos un total de 159571 filas no nulas.
Ejemplo 2: carga de una gran cantidad de datos utilizando el argumento chunksize .
Python3
df = pd.read_csv("train/train.csv", chunksize=10000)
print.print(df)
Producción:

Aquí estamos creando un fragmento de tamaño 10000 pasando el parámetro de tamaño de fragmento . El objeto devuelto no es un marco de datos sino un iterador, para obtener los datos será necesario iterar a través de este objeto.
Python3
for data in df: pprint(data.shape)
Producción:
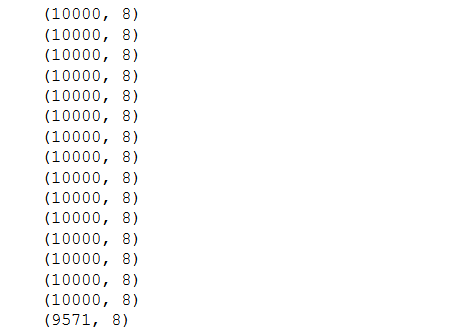
Ahora, calculando el número de trozos-
Python3
df = pd.read_csv("train/train.csv", chunksize=10)
for data in df:
pprint(data)
break
Producción:

En el ejemplo anterior, cada elemento/fragmento devuelto tiene un tamaño de 10000 . Recuerde que teníamos 159571. Por lo tanto, el número de fragmentos es 159571/10000 ~ 15 fragmentos, y los 9571 ejemplos restantes forman el fragmento 16.
El número de columnas para cada fragmento es 8. Por lo tanto, la fragmentación no afecta a las columnas. Ahora que entendemos cómo usar el tamaño de fragmento y obtener los datos, tengamos una última visualización de los datos, para fines de visibilidad, el tamaño de fragmento se asigna a 10 .
Publicación traducida automáticamente
Artículo escrito por clivefernandes777 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA