Pandas es un paquete de Python que ofrece varias estructuras de datos y operaciones para manipular datos numéricos y series temporales. Es principalmente popular para importar y analizar datos mucho más fácilmente. Es una biblioteca de código abierto que se basa en la biblioteca NumPy.
Agrupar por()
La función Pandas dataframe.groupby()se usa para dividir los datos en el marco de datos en grupos según una condición dada.
Ejemplo 1:
# import library
import pandas as pd
# import csv file
df = pd.read_csv("https://bit.ly/drinksbycountry")
df.head()
Producción: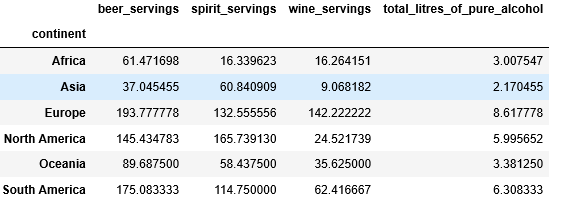
Ejemplo 2:
# Find the average of each continent # by grouping the data # based on the "continent". df.groupby(["continent"]).mean()
Producción: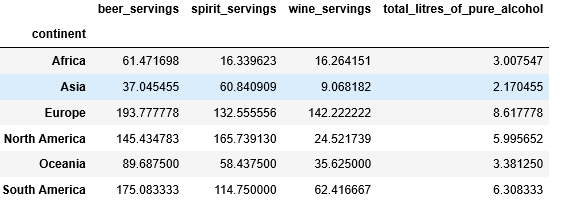
Agregar()
La función Pandas dataframe.agg()se utiliza para realizar una o más operaciones en datos basados en un eje específico
Ejemplo:
# here sum, minimum and maximum of column # beer_servings is calculatad df.beer_servings.agg(["sum", "min", "max"])
Producción:
Usando estas dos funciones juntas: podemos encontrar múltiples funciones de agregación de una columna en particular agrupadas por otra columna.
Ejemplo:
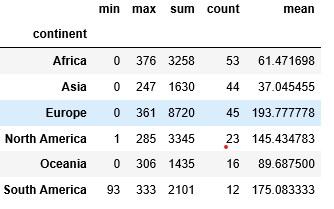
# find an aggregation of column "beer_servings" # by grouping the "continent" column. df.groupby(df["continent"]).beer_servings.agg(["min", "max", "sum", "count", "mean"])
Producción: