En este artículo, aprendemos cómo comparar las columnas en el marco de datos de los pandas. Pandas es una biblioteca muy útil en python, se usa principalmente para análisis de datos, visualización, limpieza de datos y muchos más.
Comparar las columnas es muy necesario, cuando queremos comparar los valores entre ellas o si queremos saber la similitud entre ellas. Por ejemplo, si tomamos dos columnas y queremos encontrar qué columna es mayor o menor que la otra columna o también encontrar la similitud entre ellas, Comparar la columna es lo adecuado que debemos hacer. Hay muchos tipos de métodos en pandas y NumPy para comparar los valores entre ellos. Veremos todos los métodos y la implementación en este artículo.
Método 1: Usar métodos np.where().
En este método, la condición se pasa a este método y, si la condición es verdadera, será el valor que le demos (es decir, ‘X en la sintaxis), si es falsa, será el valor que le demos. (que es ‘y’ en la sintaxis).
Sintaxis: numpy.where(condición[,x, y])
Parámetros:
- condición: cuando es verdadero, produce x, de lo contrario, produce y.
- x, y : Valores entre los que elegir.
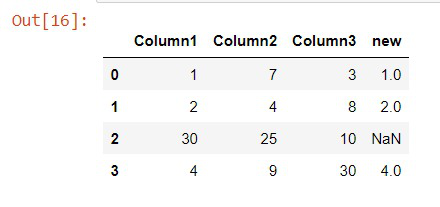
En el siguiente código, estamos importando las bibliotecas necesarias que son pandas y NumPy. Creamos un diccionario y se dan los valores para cada columna. Luego se convierte en un marco de datos de pandas. Al usar el método Where() en NumPy, se nos da la condición de comparar las columnas. Si ‘columna1’ es menor que ‘columna2’ y ‘columna1’ es menor que ‘columna3’, imprimimos los valores de ‘columna1’. Si la condición falla, damos el valor como ‘NaN’. Estos resultados se almacenan en la nueva columna en el marco de datos.
Python3
# Importing Libraries
import pandas as pd
import numpy as np
# data's stored in dictionary
details = {
'Column1': [1, 2, 30, 4],
'Column2': [7, 4, 25, 9],
'Column3': [3, 8, 10, 30]
}
# creating a Dataframe object
df = pd.DataFrame(details)
# Where method to compare the values
# The values were stored in the new column
df['new'] = np.where((df['Column1'] <= df['Column2']) & (
df['Column1'] <= df['Column3']), df['Column1'], np.nan)
# printing the dataframe
print(df)
Producción:
np.Dónde()
Método 2: Usar métodos equals().
Este método prueba si dos columnas contienen los mismos elementos. Esta función permite comparar dos Series o DataFrames entre sí para ver si tienen la misma forma y elementos. Los NaN en la misma ubicación se consideran iguales.
Sintaxis: DataFrame.equals(other)
Parámetros: OtherSeries o DataFrame: La otra Serie o DataFrame a comparar con la primera.
Devuelve: bool True si todos los elementos son iguales en ambos objetos, False en caso contrario
En el siguiente código, seguimos el mismo procedimiento, que es importar bibliotecas y crear un marco de datos. En este marco de datos, he agregado una nueva columna que es igual a la ‘columna2’ para mostrar lo que hace el método en este marco de datos.
Python3
# importing libraries
import pandas as pd
# Storing data in dictionary
details = {
'Column1': [1, 2, 3, 4],
'Column2': [7, 4, 25, 9],
'Column3': [3, 8, 10, 30],
'Column4': [7, 4, 25, 9],
}
# creating a Dataframe object
df = pd.DataFrame(details)
df['Column4'].equals(df['Column2']) # Returns True
# df['Column1'].equals(df['Column2']) Returns False
Producción:
True
Método 3: Uso de los métodos Apply().
Este método nos permite pasar la función o condición y llegar a aplicar la misma función a lo largo de la serie de tramas de datos de los pandas. Este método nos ahorra tiempo y código.
Sintaxis: DataFrame.apply(func, axis=0, raw=False, result_type=Ninguno, args=(), **kwargs)
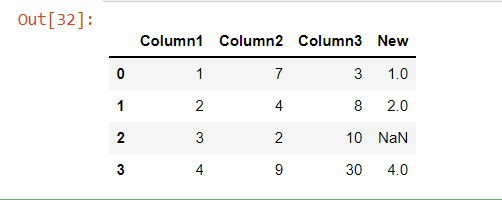
En el siguiente código, estamos repitiendo el mismo proceso para crear un marco de datos en pandas. Al usar el método apply() estamos creando una función anónima temporal hecha en apply() usando lambda. Comprueba si la ‘columna 1’ es menor que la ‘columna 2’ y si la ‘columna 1’ es menor que la ‘columna 3’. Si es Verdadero, dará el valor ‘columna1’. Si es falso, imprimirá NaN. Estos valores se almacenan dentro de la columna Nuevo. Por lo tanto, comparamos las columnas.
Python3
import pandas as pd
details = {
'Column1': [1, 2, 3, 4],
'Column2': [7, 4, 2, 9],
'Column3': [3, 8, 10, 30],
}
# creating a Dataframe object
df = pd.DataFrame(details)
# apply function
df['New'] = df.apply(lambda x: x['Column1'] if x['Column1'] <=
x['Column2'] and x['Column1']
<= x['Column3'] else np.nan, axis=1)
# printing the dataframe
print(df)
Producción:
Aplicar()
Publicación traducida automáticamente
Artículo escrito por shivapriya1726 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA