Un DataFrame es una estructura 2D compuesta de filas y columnas, y donde los datos se almacenan en forma tubular. Es mutable en términos de tamaño y datos tabulares heterogéneos. Las operaciones aritméticas también se pueden realizar en etiquetas de fila y columna.
Para saber más sobre la creación de Pandas DataFrame.
Aquí, veremos cómo comparar dos DataFrames con pandas.DataFrame.compare.
Sintaxis:
DataFrame.compare(otro, align_axis=1, keep_shape=False, keep_equal=False)
Entonces, comprendamos cada uno de sus parámetros:
- other : este es el primer parámetro que realmente toma el objeto DataFrame para compararlo con el DataFrame actual.
- align_axis : Se trata del eje (vertical/horizontal) donde se va a realizar la comparación (por defecto Falso). 0 o índice : aquí la salida de las diferencias se presenta verticalmente, 1 o columnas : la salida de las diferencias se muestra horizontalmente.
- keep_shape: significa que si queremos que todos los valores de datos se muestren en la salida o solo los que tienen un valor distinto. Es de tipo bool y su valor por defecto es “falso”, es decir, muestra por defecto todos los valores de la tabla.
- keep_equal: esto es principalmente para mostrar valores iguales o iguales en la salida cuando se establece en True. Si se hace falso, mostrará los valores iguales como NAN.
Devuelve otro DataFrame con las diferencias entre los dos dataFrames.
Antes de comenzar, una nota importante es que la versión de pandas debe ser al menos 1.1.0.
Para verificar eso, ejecute esto en su cmd o navegador Anaconda cmd.
import pandas as pd print(pd.__version__)
Si es 1.1.0 o superior, ¡ya está listo! De lo contrario, puede instalar la versión compatible con pandas mediante el comando en su ventana cmd ejecutando como administrador, o de lo contrario en su navegador Anaconda si se agrega a la ruta.
# if you want the latest version available pip install pandas --upgrade # or if you want to specify the version pip install pandas==1.1.0
Implementación:
Paso 1: crearemos nuestro primer marco de datos.
Acercarse:
- Importar pandas para DataFrame
- Importe NumPy para cualquier valor NAN que pueda surgir a través de operaciones o insertar
- Cree los DataFrames usando pandas.DataFrame y pasando el valor para sus filas, columnas
- Especifique los encabezados de las columnas (a partir del valor que ha pasado en el diccionario)
Python3
# pandas version == 1.1.0 (min)
import pandas as pd
import numpy as np
# create your first DataFrame
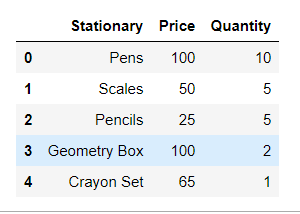
# using pd.DataFrame
first_df = pd.DataFrame(
{
"Stationary": ["Pens", "Scales",
"Pencils", "Geometry Box",
"Crayon Set"],
"Price": [100, 50, 25, 100, 65],
"Quantity": [10, 5, 5, 2, 1]
},
columns=["Stationary", "Price", "Quantity"],
)
# Display the df
first_df
Producción:
Paso 2: Ahora, hagamos el siguiente DataFrame para comparar sus valores:
Python3
# creating the second dataFrame by # copying and modifying the first DataFrame second_df = first_df.copy() # loc specifies the location, # here 0th index of Price Column second_df.loc[0, 'Price'] = 150 second_df.loc[1, 'Price'] = 70 second_df.loc[2, 'Price'] = 30 second_df.loc[0, 'Quantity'] = 15 second_df.loc[1, 'Quantity'] = 7 second_df.loc[2, 'Quantity'] = 6 # display the df second_df
Producción:

Estamos creando otro DataFrame copiando la estructura de la tabla del first_DataFrame con ciertas modificaciones. Ahora, veamos el contenido del second_DataFrame
Paso 3: hagamos nuestra operación principal: comparar.
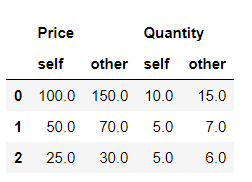
Aquí hemos realizado dos operaciones, en primer lugar para alinear las diferencias de los cambios en las columnas, para lo cual align_axis de forma predeterminada se establece en 1 y la tabla tendrá columnas dibujadas alternativamente de self y other.
Python3
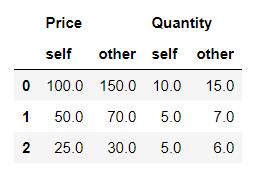
#Align the differences on the columns first_df.compare(second_df)
Producción:
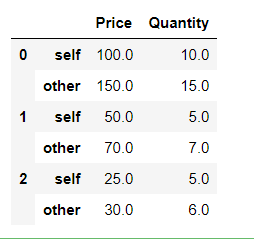
Y en segundo lugar, hemos establecido align_axis = 0, lo que hace que las filas de la tabla se extraigan alternativamente de uno mismo y de otros.
Python3
# align the differences on rows first_df.compare(second_df,align_axis=0)
Producción:
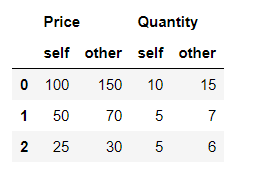
Paso 4: intentemos establecer valores iguales como verdadero y falso.
Si keep_equal es verdadero, el resultado también mantiene los valores que son iguales. De lo contrario, los valores iguales se muestran como NaN. De forma predeterminada, se establece en Falso.
Python3
# Keep the equal values first_df.compare(second_df, keep_equal=True)
Producción:
Python3
# Keep the equal values False first_df.compare(second_df, keep_equal=False)
Producción:
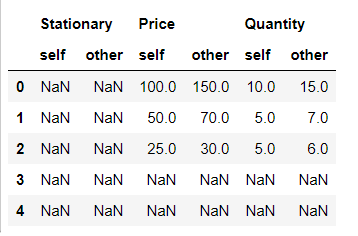
Paso 5: ahora verifiquemos el keep_shape que es falso por defecto. Si se establece en verdadero, todas las filas y columnas están presentes en la tabla, o solo se mantienen las que tienen valores distintos.
Python3
#Keep all original rows and columns first_df.compare(second_df,keep_shape=True)
Producción:
Python3
#Keep all original rows and columns and #also all original values first_df.compare(second_df,keep_shape=True, keep_equal=True)
Producción:
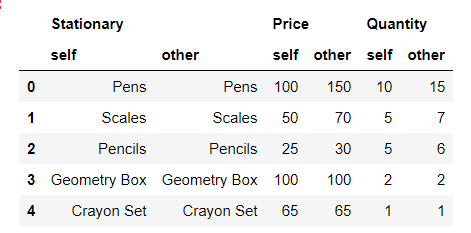
Aquí, keep_shape true mantendrá la estructura y establecerá todos los valores sin cambios en nan. Mientras que keep_shape y keep_equal true mantendrán toda la estructura de la tabla, así como también los valores que no se modifican.
Nota: antes de comparar dos tramas de datos, asegúrese de que la cantidad de registros en la primera trama de datos coincida con la cantidad de registros en la segunda trama de datos. Si no es así, obtendrá un error de valor que es:
ValueError: solo se pueden comparar objetos Series con etiquetas idénticas
Publicación traducida automáticamente
Artículo escrito por deepapandey364 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA