Veamos cómo contar duplicados en un Pandas DataFrame. Nuestra tarea es contar el número de entradas duplicadas en una sola columna y varias columnas.
Debajo de una sola columna: usaremos la pivot_table()función para contar los duplicados en una sola columna. La columna en la que se encuentran los duplicados se pasará como valor del indexparámetro. El valor de aggfunc será ‘tamaño’.
# importing the module
import pandas as pd
# creating the DataFrame
df = pd.DataFrame({'Name' : ['Mukul', 'Rohan', 'Mayank',
'Sundar', 'Aakash'],
'Course' : ['BCA', 'BBA', 'BCA', 'MBA', 'BBA'],
'Location' : ['Saharanpur', 'Meerut', 'Agra',
'Saharanpur', 'Meerut']})
# counting the duplicates
dups = df.pivot_table(index = ['Course'], aggfunc ='size')
# displaying the duplicate Series
print(dups)
Producción :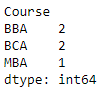
En varias columnas: usaremos la pivot_table()función para contar los duplicados en varias columnas. Las columnas en las que se encuentran los duplicados se pasarán como valor del indexparámetro en forma de lista. El valor de aggfunc será ‘tamaño’.
# importing the module
import pandas as pd
# creating the DataFrame
df = pd.DataFrame({'Name' : ['Mukul', 'Rohan', 'Mayank',
'Sundar', 'Aakash'],
'Course' : ['BCA', 'BBA', 'BCA', 'MBA', 'BBA'],
'Location' : ['Saharanpur', 'Meerut', 'Agra',
'Saharanpur', 'Meerut']})
# counting the duplicates
dups = df.pivot_table(index = ['Course', 'Location'], aggfunc ='size')
# displaying the duplicate Series
print(dups)
Producción

Publicación traducida automáticamente
Artículo escrito por mukulsomukesh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA