En este artículo, discutiremos cómo contar ID únicos después de agrupar en PySpark Dataframe.
Para ello, utilizaremos dos métodos diferentes:
- Usando el método distinto().count().
- Uso de consulta SQL.
Pero al principio, creemos un marco de datos para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql
# module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of students data
data = [["1", "sravan", "vignan", 95],
["2", "ojaswi", "vvit", 78],
["3", "rohith", "vvit", 89],
["2", "ojaswi", "vvit", 100],
["4", "sridevi", "vignan", 88],
["1", "sravan", "vignan", 78],
["4", "sridevi", "vignan", 90],
["5", "gnanesh", "iit", 67]]
# specify column names
columns = ['student ID', 'student NAME',
'college', 'subject marks']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
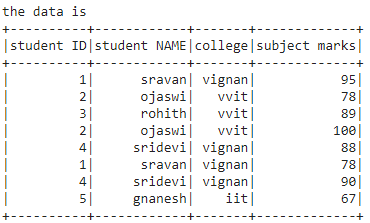
print("the data is ")
dataframe.show()
Producción:
Método 1: Usar el método groupBy() y distint().count()
groupBy(): se utiliza para agrupar los datos según el nombre de la columna
Sintaxis: dataframe=dataframe.groupBy(‘column_name1’).sum(‘column name 2’)
distinguido() .count(): se utiliza para contar y mostrar las distintas filas del marco de datos
Sintaxis: dataframe.distinct().count()
Ejemplo 1:
Python3
# group by studentID by marks
dataframe = dataframe.groupBy(
'student ID').sum('subject marks')
# display count of unique ID
print("Unique ID count after Group By : ",
dataframe.distinct().count())
print("the data is ")
# display values of unique ID
dataframe.distinct().show()
Producción:
Unique ID count after Group By : 5 the data is +----------+------------------+ |student ID|sum(subject marks)| +----------+------------------+ | 3| 89| | 5| 67| | 1| 173| | 4| 178| | 2| 178| +----------+------------------+
Ejemplo 2: Cuente y muestre una ID única de columnas individuales:
Python3
# group by studentID by marks
dataframe = dataframe.groupBy(
'student ID').sum('subject marks')
# display count of unique ID
print("Unique ID count after Group By : ",
dataframe.distinct().count())
print("the data is ")
# display values of unique ID
dataframe.select('student ID').distinct().show()
Producción:
Unique ID count after Group By : 5 the data is +----------+ |student ID| +----------+ | 3| | 5| | 1| | 4| | 2| +----------+
Método 2: Usar consulta SQL
Podemos obtener un recuento de ID único usando spark.sql
Sintaxis :
chispa.sql(“consulta sql”).show()
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql
# module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of students data
data = [["1", "sravan", "vignan", 95],
["2", "ojaswi", "vvit", 78],
["3", "rohith", "vvit", 89],
["2", "ojaswi", "vvit", 100],
["4", "sridevi", "vignan", 88],
["1", "sravan", "vignan", 78],
["4", "sridevi", "vignan", 90],
["5", "gnanesh", "iit", 67]]
# specify column names
columns = ['student ID', 'student NAME',
'college', 'subject marks']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# group by studentID by marks
dataframe = dataframe.groupBy('student ID').sum('subject marks')
# create view for the ablve dataframe and
# view name is "DATA"
dataframe.createOrReplaceTempView("DATA")
# count unique data with sql query
spark.sql("SELECT DISTINCT(COUNT('student ID')) \
FROM DATA GROUP BY 'subject marks'").show()
Producción:
+-----------------+ |count(student ID)| +-----------------+ | 5| +-----------------+
Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA