Prerrequisitos: Pandas
Groupby, como sugiere el nombre, agrupa los atributos sobre la base de la similitud en algún valor. Podemos contar los valores únicos en el objeto Pandas Groupby usando el método groupby(), agg() y reset_index(). Este artículo describe cómo se puede recuperar el recuento de valores únicos de algún atributo en un marco de datos mediante pandas.
Funciones utilizadas
- groupby() : la función groupby() se usa para dividir los datos en grupos según algunos criterios. Los objetos pandas se pueden dividir en cualquiera de sus ejes.
Sintaxis: DataFrame.groupby(by=Ninguno, axis=0, level=Ninguno, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parámetros:
- por: mapeo, función, str, o iterable
- eje: int, por defecto 0
- level : si el eje es un MultiIndex (jerárquico), agrupar por un nivel o niveles en particular
- as_index : para la salida agregada, devuelva el objeto con etiquetas de grupo como índice. Solo relevante para la entrada de DataFrame. as_index=False es efectivamente una salida agrupada de «estilo SQL»
- sort : Ordenar claves de grupo. Obtenga un mejor rendimiento desactivando esto. Tenga en cuenta que esto no influye en el orden de las observaciones dentro de cada grupo. groupby conserva el orden de las filas dentro de cada grupo.
- group_keys: al llamar a apply, agregue claves de grupo al índice para identificar piezas
- squeeze : reduce la dimensionalidad del tipo de retorno si es posible, de lo contrario, devuelve un tipo consistente
Devuelve: objeto GroupBy
- agg() : agg() se utiliza para pasar una función o una lista de funciones que se aplicarán a una serie o incluso a cada elemento de la serie por separado. En el caso de la lista de funciones, el método agg() devuelve múltiples resultados.
Sintaxis: DataFrame.aggregate(func, axis=0, *args, **kwargs)
Parámetros:
- func : invocable, string, diccionario o lista de strings/invocables. Función que se utilizará para agregar los datos. Si es una función, debe funcionar cuando se pasa un DataFrame o cuando se pasa a DataFrame.apply. Para un DataFrame, puede pasar un dict, si las claves son nombres de columna de DataFrame.
- eje: (predeterminado 0) {0 o ‘índice’, 1 o ‘columnas’} 0 o ‘índice’: aplica la función a cada columna. 1 o ‘columnas’: aplica la función a cada fila.
Devoluciones:
- reset-index() – Pandas reset_index() es un método para restablecer el índice de un marco de datos. El método reset_index() establece una lista de números enteros que van desde 0 hasta la longitud de los datos como índice.
Sintaxis: DataFrame.reset_index(level=Ninguno, drop=False, inplace=False, col_level=0, col_fill=”)
Parámetros:
- nivel: int, string o una lista para seleccionar y eliminar la columna pasada del índice.
- soltar: valor booleano, agrega la columna de índice reemplazada a los datos si es falso.
- inplace: valor booleano, realice cambios en el marco de datos original si es True.
- col_level: Seleccione en qué nivel de columna insertar las etiquetas.
- col_fill: Objeto, para determinar cómo se nombran los demás niveles.
Tipo de devolución: marco de datos
Acercarse:
- Importar bibliotecas
- hacer datos
- Datos de grupo
- Usar función agregada
- Restablecer índice
- Imprimir datos
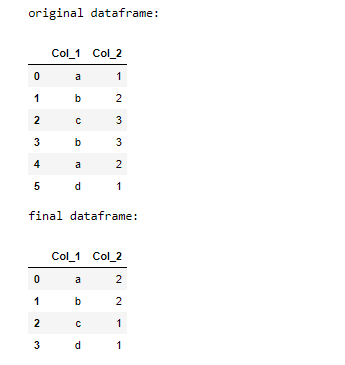
Ejemplo 1:
Python
# import pandas
import pandas as pd
# create dataframe
df = pd.DataFrame({'Col_1': ['a', 'b', 'c', 'b', 'a', 'd'],
'Col_2': [1, 2, 3, 3, 2, 1]})
# print original dataframe
print("original dataframe:")
display(df)
# call groupby method.
df = df.groupby("Col_1")
# call agg method
df = df.agg({"Col_2": "nunique"})
# call reset_index method
df = df.reset_index()
# print dataframe
print("final dataframe:")
display(df)
Producción:
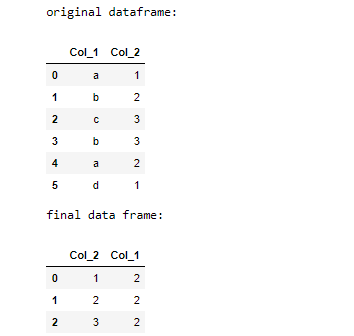
Ejemplo 2:
Python
# import pandas
import pandas as pd
# create dataframe
df = pd.DataFrame({'Col_1': ['a', 'b', 'c', 'b', 'a', 'd'],
'Col_2': [1, 2, 3, 3, 2, 1]})
# print original dataframe
print("original dataframe:")
display(df)
# call groupby method.
df = df.groupby("Col_2")
# call agg method
df = df.agg({"Col_1": "nunique"})
# call reset_index method
df = df.reset_index()
# print dataframe
print("final data frame:")
display(df)
Producción:
Publicación traducida automáticamente
Artículo escrito por deepanshu_rustagi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA