Los conjuntos de datos tienen características tanto numéricas como categóricas. Las características categóricas se refieren a tipos de datos de string y pueden ser fácilmente comprendidas por los seres humanos. Sin embargo, las máquinas no pueden interpretar los datos categóricos directamente. Por lo tanto, los datos categóricos deben convertirse en datos numéricos para su posterior procesamiento.
Hay muchas formas de convertir datos categóricos en datos numéricos. Aquí en este artículo, discutiremos los dos métodos más utilizados, a saber:
- Codificación de variables ficticias
- Codificación de etiquetas
En ambos Métodos estamos usando los mismos datos, el enlace al conjunto de datos está aquí
Método 1: Codificación de variable ficticia
Usaremos la función pandas.get_dummies para convertir los datos de strings categóricas en numéricos.
Sintaxis:
pandas.get_dummies(datos, prefijo=Ninguno, prefijo_sep=’_’, dummy_na=Falso, columnas=Ninguno, disperso=Falso, drop_first=Falso, dtype=Ninguno)
Parámetros :
- datos : Serie Pandas, o DataFrame
- prefijo : str, lista de str, o dict de str, predeterminado Ninguno. String para agregar nombres de columna de DataFrame
- prefix_sep : str, por defecto ‘_’. Si se agrega un prefijo, se utilizará un separador/delimitador.
- dummy_na : bool, por defecto Falso. Agregue una columna para indicar los NaN, si se ignoran los NaN falsos.
- columnas : como una lista, por defecto Ninguno. Nombres de columna en el DataFrame a codificar.
- disperso : booleano, predeterminado Falso. Si las columnas con codificación ficticia deben estar respaldadas por una array SparseArray (verdadero) o una array NumPy normal (falso).
- drop_first : bool, por defecto Falso. Ya sea para sacar k-1 dummies de k niveles categóricos eliminando el primer nivel.
- dtype : dtype, por defecto np.uint8. Especifica el tipo de datos para las nuevas columnas.
Devoluciones : marco de datos
Implementación paso a paso
Paso 1: Importación de bibliotecas
Python3
# importing pandas as pd import pandas as pd
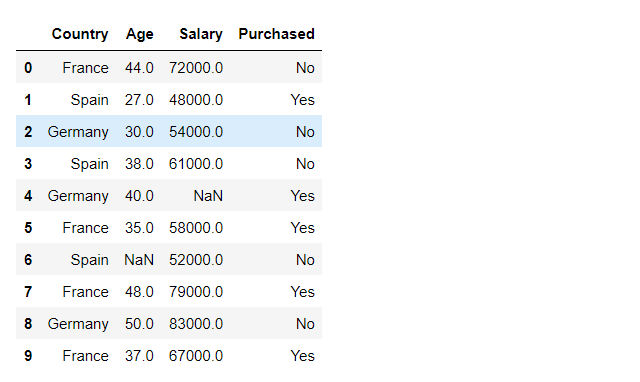
Paso 2: Importación de datos
Python3
# importing data using .read_csv() function
df = pd.read_csv('data.csv')
# printing DataFrame
df
Producción:
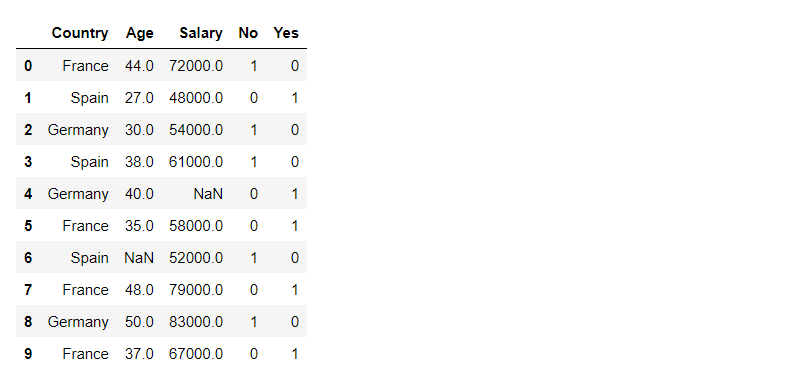
Paso 3: Conversión de columnas de datos categóricos a numéricos.
Convertiremos la columna ‘Comprado’ del tipo de datos categórico al numérico.
Python3
# using .get_dummies function to convert
# the categorical datatype to numerical
# and storing the returned dataFrame
# in a new variable df1
df1 = pd.get_dummies(df['Purchased'])
# using pd.concat to concatenate the dataframes
# df and df1 and storing the concatenated
# dataFrame in df.
df = pd.concat([df, df1], axis=1).reindex(df.index)
# removing the column 'Purchased' from df
# as it is of no use now.
df.drop('Purchased', axis=1, inplace=True)
# printing df
df
Producción:
Método 2: Codificación de etiquetas
Usaremos .LabelEncoder() de la biblioteca sklearn para convertir datos categóricos en datos numéricos. Usaremos la función fit_transform() en el proceso.
Sintaxis:
ajuste_transformar(y)
Parámetros:
- y : tipo array de forma (n_samples). Valores objetivo.
Devoluciones : tipo array de forma (n_muestras). Etiquetas codificadas.
Implementación paso a paso
Paso 1: Importación de bibliotecas
Python3
# importing pandas as pd import pandas as pd
Paso 2: Importación de datos
Python3
#importing data using .read_csv() function
df = pd.read_csv('data.csv')
#printing DataFrame
df
Producción:
Paso 3: Conversión de columnas de datos categóricos a numéricos.
Convertiremos la columna ‘Comprado’ del tipo de datos categórico al numérico.
Python3
# Importing LabelEncoder from Sklearn # library from preprocessing Module. from sklearn.preprocessing import LabelEncoder # Creating a instance of label Encoder. le = LabelEncoder() # Using .fit_transform function to fit label # encoder and return encoded label label = le.fit_transform(df['Purchased']) # printing label label
Producción:
array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
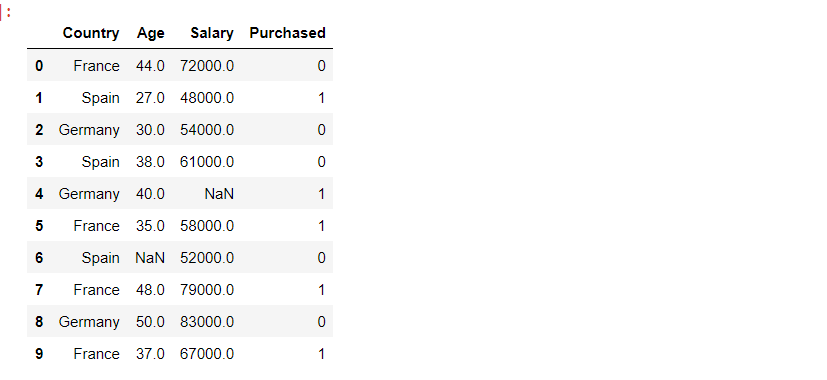
Paso 4: agregar la array de etiquetas a nuestro marco de datos
Python3
# removing the column 'Purchased' from df
# as it is of no use now.
df.drop("Purchased", axis=1, inplace=True)
# Appending the array to our dataFrame
# with column name 'Purchased'
df["Purchased"] = label
# printing Dataframe
df
Producción:
Publicación traducida automáticamente
Artículo escrito por bistpratham y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA