Pandas es una poderosa herramienta que se utiliza para el análisis de datos y se basa en la biblioteca de python. La biblioteca de Pandas permite a los usuarios crear y manipular marcos de datos (tablas de datos) y series de tiempo de manera efectiva y eficiente. Estos marcos de datos se pueden usar para entrenar y probar modelos de aprendizaje automático y analizar datos.
Convertir índice a columnas
De forma predeterminada, cada fila del marco de datos tiene un valor de índice. A las filas en el marco de datos se les asignan valores de índice de 0 a (número de filas – 1) en orden secuencial y cada fila tiene un valor de índice. Hay muchas formas de convertir un índice en una columna en un marco de datos de pandas. Vamos a crear un marco de datos.
Python3
# importing the pandas library as pd
import pandas as pd
# Creating the dataframe df
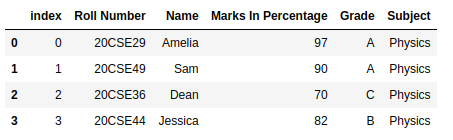
df = pd.DataFrame({'Roll Number': ['20CSE29', '20CSE49', '20CSE36', '20CSE44'],
'Name': ['Amelia', 'Sam', 'Dean', 'Jessica'],
'Marks In Percentage': [97, 90, 70, 82],
'Grade': ['A', 'A', 'C', 'B'],
'Subject': ['Physics', 'Physics', 'Physics', 'Physics']})
# Printing the dataframe
df
Producción:
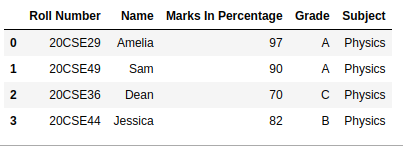
Método 1: el método más simple es crear una nueva columna y pasar los índices de cada fila a esa columna mediante la función Dataframe.index.
Python3
import pandas as pd
df = pd.DataFrame({'Roll Number': ['20CSE29', '20CSE49', '20CSE36', '20CSE44'],
'Name': ['Amelia', 'Sam', 'Dean', 'Jessica'],
'Marks In Percentage': [97, 90, 70, 82],
'Grade': ['A', 'A', 'C', 'B'],
'Subject': ['Physics', 'Physics', 'Physics', 'Physics']})
# Printing the dataframe
df['index'] = df.index
df
Producción:
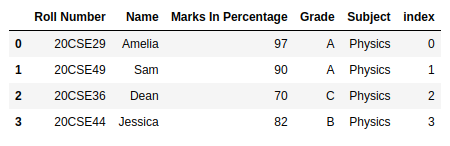
Método 2: también podemos usar la función Dataframe.reset_index para convertir el índice en una columna. El parámetro en el lugar refleja el cambio en el marco de datos para permanecer permanente.
Python3
import pandas as pd
df = pd.DataFrame({'Roll Number': ['20CSE29', '20CSE49', '20CSE36', '20CSE44'],
'Name': ['Amelia', 'Sam', 'Dean', 'Jessica'],
'Marks In Percentage': [97, 90, 70, 82],
'Grade': ['A', 'A', 'C', 'B'],
'Subject': ['Physics', 'Physics', 'Physics', 'Physics']})
# Printing the dataframe
df.reset_index(level=0, inplace=True)
df
Producción: