En este artículo, aprenderemos cómo convertir Pandas a PySpark DataFrame. A veces obtendremos datos en formato csv, xlsx, etc., y tenemos que almacenarlos en PySpark DataFrame y eso se puede hacer cargando datos en Pandas y luego convertir PySpark DataFrame. Para la conversión, pasamos el dataframe de Pandas al método CreateDataFrame().
Sintaxis: spark.createDataframe(datos, esquema)
Parámetro:
- datos: lista de valores en los que se crea el marco de datos.
- esquema: es la estructura del conjunto de datos o la lista de nombres de columna.
donde chispa es el objeto SparkSession.
Ejemplo 1: cree un marco de datos y luego conviértalo usando el método spark.createDataFrame()
Python3
# import the pandas
import pandas as pd
# from pyspark library import
# SparkSession
from pyspark.sql import SparkSession
# Building the SparkSession and name
# it :'pandas to spark'
spark = SparkSession.builder.appName(
"pandas to spark").getOrCreate()
# Create the DataFrame with the help
# of pd.DataFrame()
data = pd.DataFrame({'State': ['Alaska', 'California',
'Florida', 'Washington'],
'city': ["Anchorage", "Los Angeles",
"Miami", "Bellevue"]})
# create DataFrame
df_spark = spark.createDataFrame(data)
df_spark.show()
Producción:

Ejemplo 2: Cree un DataFrame y luego Conviértalo usando el método spark.createDataFrame()
En este método, estamos usando Apache Arrow para convertir Pandas a Pyspark DataFrame.
Python3
import the pandas
import pandas as pd
# from pyspark library import
# SparkSession
from pyspark.sql import SparkSession
# Building the SparkSession and name
# it :'pandas to spark'
spark = SparkSession.builder.appName(
"pandas to spark").getOrCreate()
# Create the DataFrame with the help
# of pd.DataFrame()
data = pd.DataFrame({'State': ['Alaska', 'California',
'Florida', 'Washington'],
'city': ["Anchorage", "Los Angeles",
"Miami", "Bellevue"]})
# enableing the Apache Arrow for converting
# Pandas to pySpark DF(DataFrame)
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
# Creating the DataFrame
sprak_arrow = spark.createDataFrame(data)
# Show the DataFrame
sprak_arrow.show()
Producción:

Ejemplo 3: cargar un marco de datos desde CSV y luego convertir
En este método, podemos leer fácilmente el archivo CSV en Pandas Dataframe, así como en Pyspark Dataframe. El conjunto de datos utilizado aquí es heart.csv .
Python3
# import the pandas library
import pandas as pd
# Read the Dataset in Pandas Dataframe
df_pd = pd.read_csv('heart.csv')
# Show the dataset here head()
# will return top 5 rows
df_pd.head()
Producción:
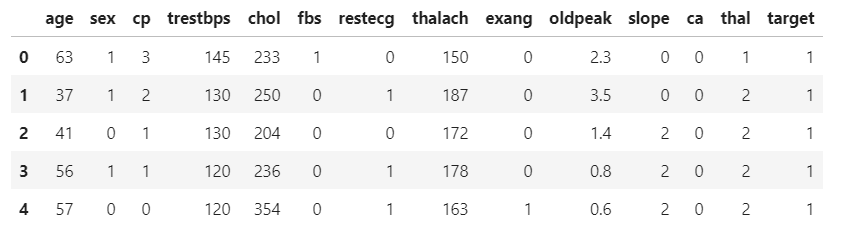
Python3
# Reading the csv file in
# Pyspark DataFrame
df_spark2 = spark.read.option(
'header', 'true').csv("heart.csv")
# Showing the data in the from of
# table and showing only top 5 rows
df_spark2.show(5)
Producción:

También podemos convertir pyspark Dataframe a pandas Dataframe. Para esto, usaremos el método DataFrame.toPandas().
Sintaxis: DataFrame.toPandas()
Devuelve el contenido de este DataFrame como Pandas pandas.DataFrame.
Python3
# Convert Pyspark DataFrame to # Pandas DataFrame by toPandas() # Function head() will show only # top 5 rows of the dataset df_spark2.toPandas().head()
Producción:
Publicación traducida automáticamente
Artículo escrito por jeetu182370 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA