En ocasiones, es posible que necesitemos datos ordenados o extensos para el análisis de datos. Entonces, en la biblioteca Pandas de python, hay algunas formas de remodelar un marco de datos que está en forma ancha en un marco de datos en forma larga/ordenada. Aquí, discutiremos la conversión de datos de una forma ancha a una forma larga usando la función stack() de pandas. stack() principalmente apila el índice especificado de columna a forma de índice. Y devuelve un DataFrame remodelado o incluso una serie que tiene un índice de varios niveles con uno o más niveles más internos nuevos en comparación con el DataFrame actual, estos niveles se crean girando las columnas del marco de datos actual y genera un:
- Serie: si las columnas tienen un solo nivel
- DataFrame: si las columnas tienen varios niveles, los nuevos niveles de índice se toman de los niveles especificados.
Sintaxis: DataFrame.stack(nivel=- 1, dropna=Verdadero)
Parámetros –
- level : Nivela para apilar desde el eje de la columna hasta el eje del índice. Toma un int, una string o una lista como valor de entrada. Y por defecto se establece en -1.
- dropna : pregunta si desea colocar las filas en el marco de datos o serie resultante en caso de que no tengan ningún valor. Es de tipo bool y por defecto se establece en True.
Devuelve un DataFrame o una serie apilados.
¡Ahora, comencemos a codificar!
Caso 1#:
En primer lugar, comencemos con una columna simple de un solo nivel y una forma amplia de datos.
Python3
import pandas as pd # Single level columns df_single_level_cols = pd.DataFrame([[74, 80], [72, 85]], index=['Deepa', 'Balram'], columns=['Maths', 'Computer']) print(df_single_level_cols)
Producción

Ahora, después de aplicar la función stack(), obtendremos un marco de datos con un eje de columna de un solo nivel que devuelve una serie:
Python3
# Single level with stack() df_single_level_cols.stack()
Producción:
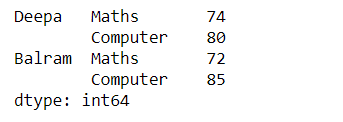
Caso 2#:
Probemos ahora con columnas de varios niveles .
Python3
# Simple Multi-level columns
multicol1 = pd.MultiIndex.from_tuples([('Science', 'Physics'),
('Science', 'Chemistry')])
df_multi_level_cols1 = pd.DataFrame([[80, 64], [76, 70]],
index=['Deepa', 'Balram'],
columns=multicol1)
print(df_multi_level_cols1)
Producción:
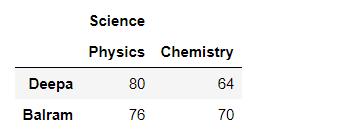
Después de apilar el marco de datos con un eje de columna de varios niveles:
Python3
# Multi-level stacking with stack df_multi_level_cols1.stack()
Producción:
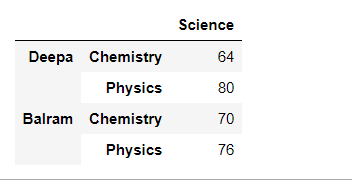
Caso 3#:
Ahora, intentemos con algunos valores que faltan en la forma ancha regular, obtendremos los valores tal como están, ya que tiene menos valor que las formas apiladas:
Python3
# Multi-level with missing values
multicol2 = pd.MultiIndex.from_tuples([('English', 'Literature'),
('Hindi', 'Language')])
df_multi_level_cols2 = pd.DataFrame([[80, 75], [80, 85]],
index=['Deepa', 'Balram'],
columns=multicol2)
df_multi_level_cols2
Producción:
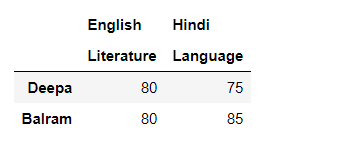
Pero cuando lo apilamos,
Podemos tener valores faltantes al apilar un marco de datos con columnas de varios niveles, ya que el marco de datos apilado generalmente tiene más valores que el marco de datos original. Los valores que faltan se llenan con NaN, como aquí en este ejemplo, el valor para el idioma inglés no se conoce, por lo que se llena con NaN.
Python3
# Multi-level missing values as NaN df_multi_level_cols2.stack()
Producción:
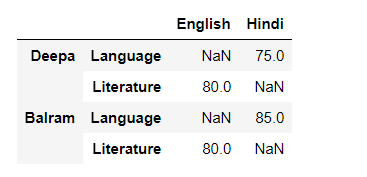
Caso 4#:
Aparte de eso, también podemos contener los valores apilados según nuestras preferencias, por lo tanto, prescribiendo a la pila el valor que se debe mantener. El primer parámetro controla realmente qué nivel o niveles se apilan. Me gusta,
Python3
# Prescribing the level(s) to be stacked df_multi_level_cols2.stack(0) # The first parameter controls which level # or levels are stacked df_multi_level_cols2.stack([0, 1])
Producción:

Caso 5#:
Ahora, finalmente, veamos cuál es el propósito del dropna en stack(). Para esto, eliminaremos las filas que tienen valores completamente NaN. Verifiquemos el código para obtener el resultado regular cuando se incluyen los valores de NaN.
Python3
# Dropping missing values df_multi_level_cols3 = pd.DataFrame([[None, 80], [77, 82]], index=['Deepa', 'Balram'], columns=multicol2) print(df_multi_level_cols3) # contains the row with all NaN values since, # dropna=False df_multi_level_cols3.stack(dropna=False) print(df_multi_level_cols3)
Producción:
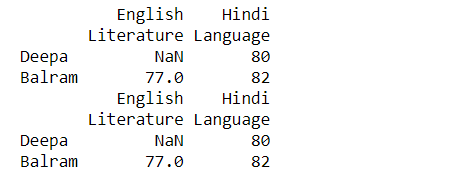
Aquí, podemos ver en el índice Deepa, el valor de Literatura es NaN cuando estamos operando con dropna = False (también incluye el valor NaN)
Verifiquemos cuándo hacemos dropna = True (omite la fila completa de valores de NaN)
Python3
# Drops the row with completely NaN values df_multi_level_cols3.stack(dropna=True) print(df_multi_level_cols3)
Producción:

Entonces, aquí haciendo dropna = False omite la fila de Literatura como un todo, ya que era NaN por completo.
Publicación traducida automáticamente
Artículo escrito por deepapandey364 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA