En este artículo, vamos a discutir la creación del marco de datos Pyspark a partir de la lista de diccionarios.
Vamos a crear un dataframe en PySpark usando una lista de diccionarios con la ayuda del método createDataFrame(). El atributo de datos toma la lista de diccionarios y el atributo de columnas toma la lista de nombres.
marco de datos = chispa.createDataFrame (datos, columnas)
Ejemplo 1:
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of dictionaries of students data
data = [{"Student ID": 1, "Student name": "sravan"},
{"Student ID": 2, "Student name": "Jyothika"},
{"Student ID": 3, "Student name": "deepika"},
{"Student ID": 4, "Student name": "harsha"}]
# creating a dataframe
dataframe = spark.createDataFrame(data)
# display dataframe
dataframe.show()
Producción:

Ejemplo 2:
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of dictionaries of crop data
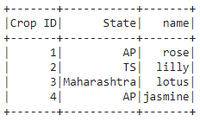
data = [{"Crop ID": 1, "name": "rose", "State": "AP"},
{"Crop ID": 2, "name": "lilly", "State": "TS"},
{"Crop ID": 3, "name": "lotus", "State": "Maharashtra"},
{"Crop ID": 4, "name": "jasmine", "State": "AP"}]
# creating a dataframe
dataframe = spark.createDataFrame(data)
# display dataframe
dataframe.show()
Producción:
Ejemplo 3:
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of dictionaries of crop data
data = [{"Crop ID": 1, "name": "rose", "State": "AP"},
{"Crop ID": 2, "name": "lilly", "State": "TS"},
{"Crop ID": 3, "name": "lotus", "State": "Maharashtra"},
{"Crop ID": 4, "name": "jasmine", "State": "AP"}]
# creating a dataframe
dataframe = spark.createDataFrame(data)
# display dataframe count
dataframe.count()
Producción:
4
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA