En este artículo, corregiremos el error: las columnas se superponen pero no se especifica un sufijo en Python.
Este error ocurre cuando unimos dos marcos de datos de pandas que tienen una o más columnas iguales pero no se especifica un sufijo para diferenciarlos.
Error:
ValueError: las columnas se superponen pero no se especifica el sufijo
Caso de esta ocurrencia de error por un ejemplo:
Python3
# importing pandas
import pandas as pd
# importing numpy
import numpy as np
sepal_length = [5.1, 4.9, 4.7, 4.6, 5.0,
5.4, 4.2, 5.3, 4.4, 4.8]
petal_length = [3.3, 4.6, 4.7, 5.6, 6.7,
5.0, 4.8, 4.1, 3.6, 4.4]
# numpy array of length 7
petal_width = [3.6, 5.6, 5.4, 4.6, 4.4,
5.0, 4.9, 5.6, 5.2, 4.4]
# DataFrame with 2 columns of length 10
df1 = pd.DataFrame({'sepal_length(cm)': sepal_length,
'petal_length(cm)': petal_length})
df2 = pd.DataFrame({'sepal_length(cm)': sepal_length,
'petal_width(cm)': petal_width})
print(df1.join(df2))
Producción:
ValueError: las columnas se superponen pero no se especifica el sufijo: Index([‘sepal_length(cm)’], dtype=’object’)
Motivo del error:
Los marcos de datos df1 y df2 tienen la columna común sepal_length(cm) que es la intersección de dos marcos de datos que no está vacía. Para verificar si hay columnas de intersección:
print(df1.columns.intersection(df2.columns))
Producción:
Index(['sepal_length(cm)'], dtype='object')
sepal_length(cm) es la columna de intersección aquí.
Arreglando el error:
Este error se puede solucionar utilizando el método join() o merge() en los dos marcos de datos.
Método 1: Usar el método join()
Los sufijos deben proporcionarse mientras se usa el método de unión para evitar este error. De forma predeterminada, realiza una unión interna en dos tablas. Esto se puede cambiar mencionando los parámetros en la función join().
Sintaxis :
df1.join(df2, lsuffix='suffix_name', rsuffix='suffix_name')
dónde
- df1 es el primer marco de datos
- df2 es el segundo marco de datos
Ejemplo :
Python3
# importing pandas
import pandas as pd
# importing numpy
import numpy as np
sepal_length = [5.1, 4.9, 4.7, 4.6, 5.0, 5.4,
4.2, 5.3, 4.4, 4.8]
petal_length = [3.3, 4.6, 4.7, 5.6, 6.7, 5.0,
4.8, 4.1, 3.6, 4.4]
# numpy array of length 7
petal_width = [3.6, 5.6, 5.4, 4.6, 4.4, 5.0,
4.9, 5.6, 5.2, 4.4]
# DataFrame with 2 columns of length 10
df1 = pd.DataFrame({'sepal_length(cm)': sepal_length,
'petal_length(cm)': petal_length})
df2 = pd.DataFrame({'sepal_length(cm)': sepal_length,
'petal_width(cm)': petal_width})
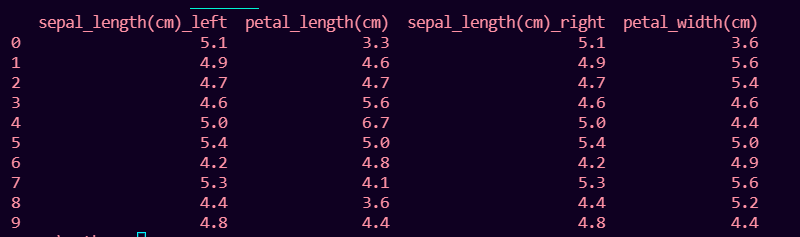
print(df1.join(df2, lsuffix='_left', rsuffix='_right'))
Producción:
Método 2: Usar el método merge()
Este método merge() considera la columna común en los 2 marcos de datos y descarta la columna común en uno de los marcos de datos.
Sintaxis :
pd.merge(df1,df2, how='join_type', on=None, left_on= None, right_on = None, left_index =boolean, right_index=boolean, sort=boolean)
dónde,
- df1 es el primer marco de datos
- df2 es el segundo marco de datos
El tipo de unión y los nombres de las columnas comunes de los marcos de datos izquierdo y derecho también se pueden mencionar como parámetros en la función merge().
Ejemplo:
Python3
# importing pandas
import pandas as pd
# importing numpy
import numpy as np
sepal_length = [5.1, 4.9, 4.7, 4.6, 5.0, 5.4,
4.2, 5.3, 4.4, 4.8]
petal_length = [3.3, 4.6, 4.7, 5.6, 6.7, 5.0,
4.8, 4.1, 3.6, 4.4]
# numpy array of length 7
petal_width = [3.6, 5.6, 5.4, 4.6, 4.4, 5.0,
4.9, 5.6, 5.2, 4.4]
# DataFrame with 2 columns of length 10
df1 = pd.DataFrame({'sepal_length(cm)': sepal_length,
'petal_length(cm)': petal_length})
df2 = pd.DataFrame({'sepal_length(cm)': sepal_length,
'petal_width(cm)': petal_width})
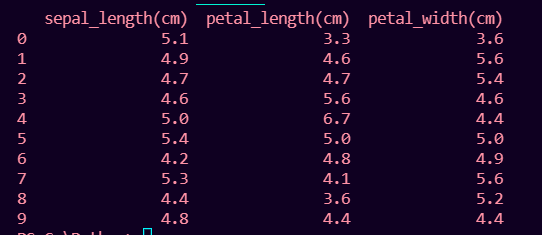
print(pd.merge(df1, df2))
Producción:
Publicación traducida automáticamente
Artículo escrito por lokeshpotta20 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA