En este artículo corregiremos el error: Todas las arrays deben tener la misma longitud. Obtenemos este error cuando creamos un marco de datos de pandas con columnas de diferentes longitudes, pero cuando creamos un marco de datos de pandas, las columnas deben ser iguales, en lugar de eso, puede haber NaN en la celda deficiente de la columna.
Error:
ValueError: All arrays must be of the same length
Casos de esta ocurrencia de error por un ejemplo:
Python3
# import pandas module
import pandas as pd
# consider the lists
sepal_length = [5.1, 4.9, 4.7, 4.6, 5.0, 5.4,
4.6, 5.0, 4.4, 4.9]
sepal_width = [4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9]
# DataFrame with two columns
df = pd.DataFrame({'sepal_length(cm)': sepal_length,
'sepal_width(cm)': sepal_width})
# display
print(df)
Producción:
ValueError: arrays must all be same length
Motivo del error:
La longitud de la lista sepal_length que va a ser la columna no era igual a la longitud de la lista sepal_witdth columna.
len(sepal_length)!= len(sepal_width)
Arreglando el error:
El error se puede corregir agregando los valores a la lista deficiente o eliminando la lista con una longitud mayor si tiene algunos valores inútiles. Se puede agregar NaN o cualquier otro valor al valor deficiente en función de la observación de los valores restantes en la lista.
Sintaxis:
Considerando dos listas lista1 y lista2:
if (len(list1) > len(list2)):
list2 += (len(list1)-len(list2)) * [any_suitable_value]
elif (len(list1) < len(list2)):
list1 += (len(list2)-len(list1)) * [any_suitable_value]
Aquí, cualquier_valor_adecuado puede ser un promedio de la lista o 0 o NaN según el requisito.
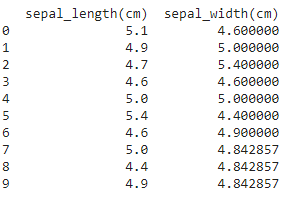
Ejemplo :
Python3
# importing pandas
import pandas as pd
# importing statistics
import statistics as st
# consider the lists
sepal_length = [5.1, 4.9, 4.7, 4.6, 5.0, 5.4,
4.6, 5.0, 4.4, 4.9]
sepal_width = [4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9]
# if length are not equal
if len(sepal_length) != len(sepal_width):
# Append mean values to the list with smaller length
if len(sepal_length) > len(sepal_width):
mean_width = st.mean(sepal_width)
sepal_width += (len(sepal_length)-len(sepal_width)) * [mean_width]
elif len(sepal_length) < len(sepal_width):
mean_length = st.mean(sepal_length)
sepal_length += (len(sepal_width)-len(sepal_length)) * [mean_length]
# DataFrame with 2 columns
df = pd.DataFrame({'sepal_length(cm)': sepal_length,
'sepal_width(cm)': sepal_width})
print(df)
Salida :
Publicación traducida automáticamente
Artículo escrito por lokeshpotta20 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA