En este artículo vamos a ver cómo crear tablas de frecuencia en Python
La frecuencia es un recuento del número de ocurrencias de un valor particular que ocurre o aparece en nuestros datos. Una tabla de frecuencia muestra un conjunto de valores junto con la frecuencia con la que aparecen. Nos permiten comprender mejor qué valores de datos son comunes y cuáles son poco comunes. Estas tablas son un excelente método para organizar sus datos y comunicar los resultados a otros. En este artículo, demostremos las diferentes formas en que podemos crear tablas de frecuencia en python.
Para ver y descargar el archivo CSV que usamos en este artículo, haga clic aquí .
Método 1: tabla de frecuencia simple usando el método value_counts()
Echemos un vistazo al conjunto de datos en el que trabajaremos:
Los paquetes necesarios se importan y el conjunto de datos se lee mediante el método pandas.read_csv() . El método df.head() devuelve las primeras 5 filas del conjunto de datos.
Python3
# import packages
import pandas as pd
import numpy as np
# reading csv file as pandas dataframe
data = pd.read_csv('iris.csv')
data.head()
Producción:
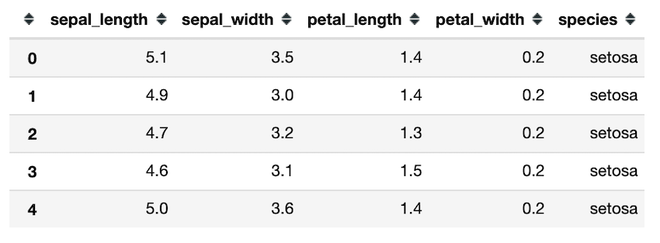
Ahora encontremos la tabla de frecuencia unidireccional de la columna de especies del conjunto de datos.
Python3
df = data['species'].value_counts() print(df)
Producción:
setosa 50 virginica 50 versicolor 50 Name: species, dtype: int64
Método 2: tabla de frecuencia unidireccional usando el método pandas.crosstab()
Aquí vamos a utilizar el método crosstab() para obtener la frecuencia.
Sintaxis: pandas.crosstab(índice, columnas, valores=Ninguno, nombres de filas=Ninguno, nombres de columnas=Ninguno, aggfunc=Ninguno, márgenes=False, margins_name=’All’, dropna=True, normalize=False)
Parámetros:
- índice: array o serie que contiene valores para agrupar en las filas.
- columnas: array o serie que contiene valores para agrupar en las columnas. es el nombre que le damos a la columna que encontramos frecuencia
- valores : una array de números que se agregarán en función de los factores.
En el siguiente código usamos la función de tabulación cruzada donde damos la columna de especies como un índice y ‘no_of_species’ como el nombre de la columna de frecuencia.
Python3
# import packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# reading csv file as pandas dataframe
data = pd.read_csv('iris.csv')
# one way frequency table for the species column.
freq_table = pd.crosstab(data['species'], 'no_of_species')
freq_table
Resultado: 50 plantas pertenecientes a la especie setosa, 50 de Versicolor y 50 de Virginica.
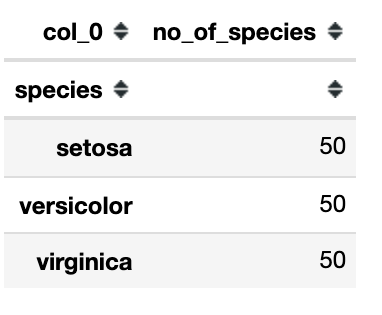
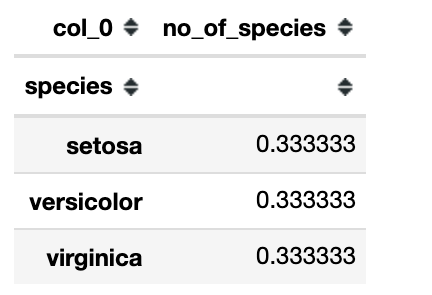
Si queremos que la tabla de frecuencias esté en proporciones, entonces tenemos que dividir cada proporción individual por la suma del número total.
Python3
# import packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# reading csv file as pandas dataframe
data = pd.read_csv('iris.csv')
# one way frequency table for the species column.
freq_table = pd.crosstab(data['species'], 'no_of_species')
# frequency table in proportion of species
freq_table= freq_table/len(data)
freq_table
Salida: 0,333 indica que el 0,333 % de la población total es setosa y así sucesivamente.
Método 3: tabla de frecuencia bidireccional usando el método pandas.crosstab()
La tabla de frecuencia bidireccional es donde creamos una tabla de frecuencia para dos características diferentes en nuestro conjunto de datos. Para descargar y revisar el archivo CSV utilizado en este ejemplo, haga clic aquí . En el siguiente ejemplo, creamos una tabla de frecuencia bidireccional para el modo de barco y las columnas de segmento de nuestro conjunto de datos.
Python3
# import packages
import pandas as pd
import numpy as np
# reading csv file
data = pd.read_csv('SampleSuperstore.csv')
# two way frequency table for the ship mode column
# and consumer column of the superstore dataset.
freq_table = pd.crosstab(data['Ship Mode'], data['Segment'])
freq_table
Producción:
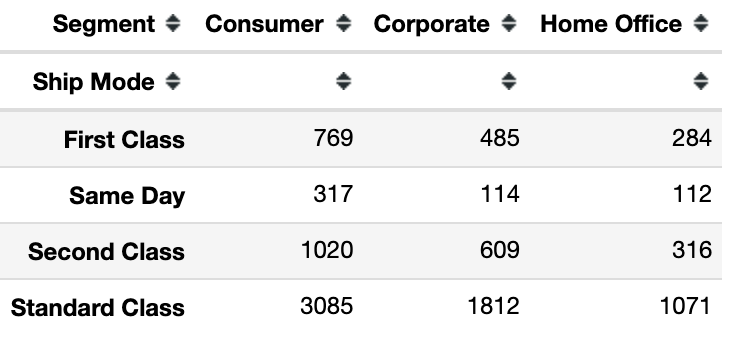
Podemos interpretar esta tabla como que para el modo de barco de primera clase hay 769 segmentos de consumidores, 485 segmentos corporativos y 284 segmentos de oficinas en el hogar, y así sucesivamente.
Publicación traducida automáticamente
Artículo escrito por isitapol2002 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA