En este artículo, discutiremos cómo crear tablas de resumen en el lenguaje de programación R.
La tabla resumen contiene la siguiente información:
- vars: representa el número de columna
- n: representa el número de casos válidos
- media: representa el valor medio
- mediana: representa el valor de la mediana
- trimmed : representa la media recortada
- mad : representa la desviación absoluta mediana
- min : representa el valor mínimo
- max : representa el valor máximo
- range : representa el rango de valores
- skew : representa la asimetría
- curtosis : representa la curtosis
- se : representa el error estándar
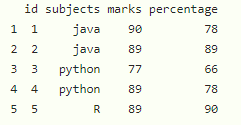
Marco de datos inicial:
Vamos a crear un marco de datos con 5 filas y 4 columnas.
R
# create dataframe
data = data.frame(id=c(1, 2, 3, 4, 5),
subjects=c("java", "java", "python",
"python", "R"),
marks=c(90, 89, 77, 89, 89),
percentage=c(78, 89, 66, 78, 90))
# display
data
Producción:
Método 1: usar la función Describe() con el marco de datos
En este método para crear una tabla de resumen, el usuario debe importar e instalar el paquete psych en la consola R en funcionamiento actual y luego llamar a la función describe() de este paquete. Esta función debe pasarse con el nombre del marco de datos dado como parámetro para obtener la tabla de resumen a cambio de los datos pasados como su parámetro en el lenguaje de programación R.
Sintaxis para instalar e importar el paquete psych en la consola R:
install.package("psych")
library("psych")
describir la función:
Esta función proporciona las más útiles para la construcción de escalas y análisis de ítems en psicometría clásica.
Sintaxis:
describe(dataframe)
Parámetros:
- marco de datos: es el marco de datos de entrada
Ejemplo:
En este ejemplo, simplemente usaremos la función describe() para obtener el resumen del marco de datos dado con 5 filas y 4 columnas en lenguaje R.
R
# load the library
library(psych)
# create dataframe
data=data.frame(id=c(1,2,3,4,5),
subjects=c("java","java","python","python","R"),
marks=c(90,89,77,89,89),
percentage=c(78,89,66,78,90))
# get the summary table
describe(data)
Producción:

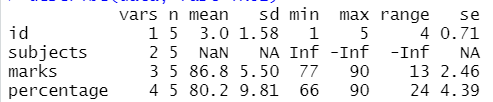
Método 2: Usar Describe() con parámetro rápido
En este método, el usuario tiene que usar el parámetro adicional de la función describe(). Si queremos obtener solo vars, n, mean, sd, min, max, range, see, y luego tenemos que especificar el parámetro rápido que se establece en verdadero para obtener el resumen de los datos dados en el lenguaje de programación r.
Sintaxis :
describe(dataframe,fast=TRUE)
Ejemplo:
en este ejemplo, vamos a describir el marco de datos para mostrar la media, el valor mínimo, el valor máximo, el rango y la desviación estándar.
R
# load the library
library(psych)
# create dataframe
data = data.frame(id=c(1, 2, 3, 4, 5),
subjects=c("java", "java", "python", "python", "R"),
marks=c(90, 89, 77, 89, 89),
percentage=c(78, 89, 66, 78, 90))
# get the summary table
describe(data, fast=TRUE)
Producción:
Método 3: crear una tabla de resumen de la columna en particular
En este enfoque para crear la tabla de resumen de una columna en particular, el usuario debe crear un vector de los nombres de las columnas y pasarlo como parámetro de la función de descripción para obtener el resumen de los nombres de las columnas proporcionados del marco de datos en la programación R. idioma.
Sintaxis:
describe(dataframe[ , c('column1', 'column2',........,'column n')],fast=TRUE)
Ejemplo :
En este ejemplo, vamos a obtener la tabla de resumen de materias y porcentajes utilizando la función de descripción en el lenguaje R.
R
# load the library
library(psych)
# create dataframe
data=data.frame(id=c(1,2,3,4,5),
subjects=c("java","java","python","python","R"),
marks=c(90,89,77,89,89),
percentage=c(78,89,66,78,90))
# get the summary table for subjects and percentage
describe(data[ , c('subjects', 'percentage')],fast=TRUE)
Producción:

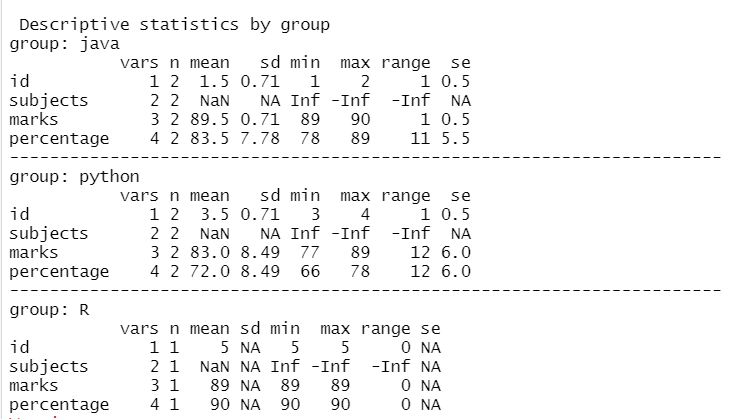
Método 4: usar el argumento de grupo de la función de descripción
En este enfoque, el usuario puede obtener la tabla de resumen agrupándola con otra columna con la función describe() simplemente usando el argumento de grupo e inicializándolo con el grupo de nombres de columna que se necesita resumir en el lenguaje r.
Sintaxis:
describeBy(dataframe, group=dataframe$column_name, fast=TRUE)
dónde
- grupo: es agrupar la columna en base a esta columna
Ejemplo :
En este ejemplo, obtenemos la tabla de resumen al agrupar sujetos con el porcentaje usando el argumento de grupo de la función describe() en el lenguaje R.
R
# load the library
library(psych)
# create dataframe
data=data.frame(id=c(1,2,3,4,5),
subjects=c("java","java","python","python","R"),
marks=c(90,89,77,89,89),
percentage=c(78,89,66,78,90))
# get the summary table for group with
# subjects to percentage
describeBy(data, group=data$subjects, fast=TRUE)
Producción:
Publicación traducida automáticamente
Artículo escrito por 171fa07058 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA