En este artículo, discutiremos cómo crear el marco de datos con el esquema usando PySpark. En palabras simples, el esquema es la estructura de un conjunto de datos o marco de datos.
Funciones utilizadas:
| Función | Descripción |
|---|---|
| SparkSession | El punto de entrada a Spark SQL. |
| SparkSession.constructor() | Da acceso a la API de Builder que usamos para configurar la sesión. |
| SparkSession.master (local) | Establece la URL principal de Spark para conectarse y ejecutarse localmente. |
| SparkSession.nombre de la aplicación() | Establece el nombre de la aplicación. |
| SparkSession.getOrCreate() | Si no hay una sesión de Spark existente, crea una nueva; de lo contrario, usa la existente. |
Para crear el marco de datos con el esquema que estamos usando:
Sintaxis: spark.createDataframe(datos,esquema)
Parámetro:
- datos: lista de valores en los que se crea el marco de datos.
- esquema: es la estructura del conjunto de datos o la lista de nombres de columna.
donde chispa es el objeto SparkSession.
Ejemplo 1:
- En el siguiente código, estamos creando un nuevo objeto Spark Session llamado ‘spark’.
- Luego, creamos los valores de datos y los almacenamos en la variable llamada ‘datos’ para crear el marco de datos.
- Luego definimos el esquema para el marco de datos y lo almacenamos en la variable llamada ‘schm’.
- Luego, hemos creado el marco de datos mediante el uso de la función createDataframe() en la que hemos pasado los datos y el esquema para el marco de datos.
- Como el marco de datos se crea para visualizar, usamos la función show().
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Geek_examples.com") \
.getOrCreate()
return spk
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
# creating data for creating dataframe
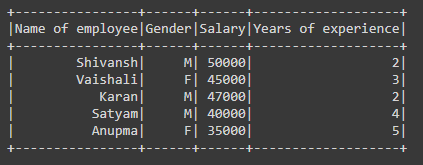
data = [
("Shivansh","M",50000,2),
("Vaishali","F",45000,3),
("Karan","M",47000,2),
("Satyam","M",40000,4),
("Anupma","F",35000,5)
]
# giving schema
schm=["Name of employee","Gender","Salary","Years of experience"]
# creating dataframe using createDataFrame()
# function in which pass data and schema
df = spark.createDataFrame(data,schema=schm)
# visualizing the dataframe using show() function
df.show()
Producción:
Ejemplo 2:
En el siguiente código, estamos creando el marco de datos pasando datos y esquemas en la función createDataframe() directamente.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Geek_examples.com") \
.getOrCreate()
return spk
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
# creating dataframe using createDataFrame()
# function in which pass data and schema
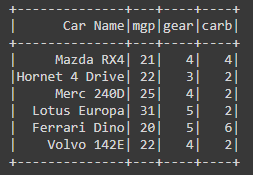
df = spark.createDataFrame([
("Mazda RX4",21,4,4),
("Hornet 4 Drive",22,3,2),
("Merc 240D",25,4,2),
("Lotus Europa",31,5,2),
("Ferrari Dino",20,5,6),
("Volvo 142E",22,4,2)
],["Car Name","mgp","gear","carb"])
# visualizing the dataframe using show() function
df.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA