En este artículo, aprenderemos cómo crear una lista de archivos, carpetas y subcarpetas y luego exportarlos a Excel usando Python. Crearemos una lista de nombres y rutas utilizando algunos métodos de desplazamiento de carpetas que se explican a continuación y los almacenaremos en una hoja de Excel utilizando el módulo openpyxl o pandas.
Entrada: La siguiente imagen representa la estructura del directorio.
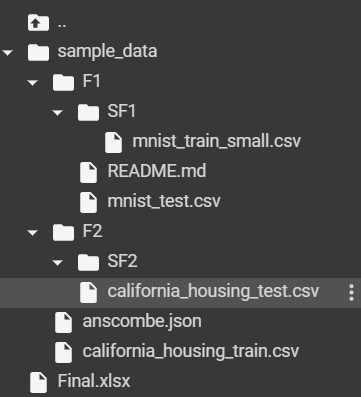
NOTA: SF2 es un directorio vacío
Atravesar archivos, carpetas y subcarpetas
Las siguientes funciones son métodos para recorrer carpetas y almacenan el nombre y la ruta de los archivos/carpetas en listas.
Método 1: Usar append_path_name(path, name_list, path_list, glob)
Una función importante que se utiliza en las siguientes funciones de desplazamiento de carpetas. El propósito de la función es verificar si la ruta dada es del sistema operativo Windows o Linux, ya que el separador de rutas es diferente y agrega los nombres y las rutas de los archivos o carpetas a name_list y path_list respectivamente.
Nota: Windows usa «\» y Linux usa «/» como separador de ruta, dado que Python trata «\» como un carácter no válido, necesitamos usar «\\» en lugar de «\» en la ruta.
Acercarse:
- La función primero encontrará si la ruta contiene «\\» usando:
# Returns the count if it finds
# any "\\" in the given path.
path.find("\\")
Nota: Si devuelve cualquier número mayor que cero, significa que el sistema operativo actual es Windows y se ejecutará el primer bloque de código o, de lo contrario, se ejecutará el segundo bloque de código que representa el sistema operativo Linux.
- Dividiremos la ruta de acuerdo con el sistema operativo actual y la almacenaremos en una lista temporal.
# Windows
temp = path.split("\\")
# Linux
temp = path.split("/")
- Agregaremos el nombre y la ruta de los archivos o carpetas a name_list y path_list respectivamente.
# temp[-1] gets the last value present in # the temporary list that represents # the file or folder name. name_list.append(temp[-1]) path_list.append(path)
- Si la variable glob es True, la ruta principal se unirá con una expresión regular que se requiere para el recorrido recursivo en el método glob.iglob().
# Windows path = os.path.join(path, "**\\*") # Linux path = os.path.join(path, "**/*")
Ejemplo:
Python3
import os
# This function splits the path by checking
# if it is a windows os or linux os path and
# appends the name and path of directory (and
# files only for glob function).
def append_path_name(path, name_list, path_list, glob):
# Checks if it is a windows path or linux
# path
if path.find("\\") > 0:
# Splits the windows path and stores the
# list in a temp list and appends the last
# value of temp_list in name_list as it
# represents the name of file/ folder and
# also appends the path to path_list.
temp = path.split("\\")
name_list.append(temp[-1])
path_list.append(path)
# If this function is called under
# find_using_glob then we return modified
# path so that iglob can recursively
# traverse the folders.
if glob == True:
path = os.path.join(path, "**\\*")
return path, name_list, path_list
else:
# Same explanation as above but the path splitting
# is based on Linux
temp = path.split("/")
name_list.append(temp[-1])
path_list.append(path)
if glob == True:
path = os.path.join(path, "**/*")
return path, name_list, path_list
return name_list, path_list
name_list, path_list = append_path_name("/content/sample_data", [], [], False)
print(name_list)
print(path_list)
Producción:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Método 2: Usar find_using_os_walk(ruta, lista_de_nombres, lista_de_rutas)
Este método genera los nombres de los archivos en un árbol de directorios recorriendo el árbol de arriba hacia abajo o de abajo hacia arriba en la ruta dada.
Sintaxis: os.walk ( ruta )
Acercarse:
1. Inicie un ciclo for usando el método os.walk(ruta), genera una tupla que contiene la ruta del directorio actual en la raíz y la lista de archivos en archivos.
for root, _, files in os.walk(path):
2. Llame a la función append_path_name para almacenar los nombres y las rutas de los directorios sin pasar por la ruta del directorio actual.
name_list, path_list = append_path_name(
root, name_list, path_list, False)
3. Iterar los archivos y almacenar los nombres y las rutas de los archivos que se encuentran dentro de una carpeta.
# Joins the folder path and the # file name to generate file path file_path = os.path.join(root, file_name) # Appends file name and file path to # name_list and path_list respectively. name_list.append(file_name) path_list.append(file_path)
Ejemplo:
Python3
import os
# This Function uses os.walk method to traverse folders
# recursively and appends the name and path of file/
# folders in name_list and path_list respectively.
def find_using_os_walk(path, name_list, path_list):
for root, _, files in os.walk(path):
# Function returns modified name_list and
# path_list.
name_list, path_list = append_path_name(
root, name_list, path_list, False)
for file_name in files:
file_path = os.path.join(root, file_name)
# Appends file name and file path to
# name_list and path_list respectively.
name_list.append(file_name)
path_list.append(file_path)
return name_list, path_list
name_list, path_list = find_using_os_walk("/content/sample_data", [], [])
print(name_list)
print(path_list)
Producción:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Método 3: Uso de find_using_scandir (ruta, lista de nombres, lista de rutas)
Esta función devuelve un iterador de objetos os.DirEntry correspondientes a las entradas en el directorio proporcionado por la ruta.
Sintaxis: os.scandir ( ruta )
Acercarse:
1. Llame a la función append_path_name para almacenar los nombres y las rutas de los directorios pasando la ruta del directorio actual.
name_list, path_list = append_path_name(
path, name_list, path_list, False)
2. Inicie un bucle for utilizando el método os.scandir(ruta) que devuelve un objeto que contiene el nombre y la ruta actuales del archivo/carpeta.
for curr_path_obj in os.scandir(path):
3. Si la ruta actual es un directorio, la función se llama a sí misma para recorrer recursivamente las carpetas y almacenar los nombres de las carpetas y las rutas del paso 1.
if curr_path_obj.is_dir() == True: file_path = curr_path_obj.path find_using_scandir(file_path, name_list, path_list)
4. De lo contrario, los nombres de archivo y las rutas se almacenan en name_list y path_list respectivamente.
file_name = curr_path_obj.name file_path = curr_path_obj.path name_list.append(file_name) path_list.append(file_path)
Ejemplo:
Python3
import os
# This Function uses os.scandir method to traverse
# folders recursively and appends the name and path of
# file/folders in name_list and path_list respectively.
def find_using_scandir(path, name_list, path_list):
# Function returns modified name_list and path_list.
name_list, path_list = append_path_name(
path, name_list, path_list, False)
for curr_path_obj in os.scandir(path):
# If the current path is a directory then the
# function calls itself with the directory path
# and goes on until a file is found.
if curr_path_obj.is_dir() == True:
file_path = curr_path_obj.path
find_using_scandir(file_path, name_list, path_list)
else:
# Appends file name and file path to
# name_list and path_list respectively.
file_name = curr_path_obj.name
file_path = curr_path_obj.path
name_list.append(file_name)
path_list.append(file_path)
return name_list, path_list
name_list, path_list = find_using_scandir("/content/sample_data", [], [])
print(name_list)
print(path_list)
Producción:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Método 4: Uso de find_using_listdir(ruta, lista_de_nombres, lista_de_rutas)
Esta función obtiene la lista de todos los archivos y directorios en la ruta dada.
Sintaxis: os.listdir ( ruta )
Acercarse:
1. Llame a la función append_path_name para almacenar los nombres y las rutas de los directorios pasando la ruta del directorio actual.
name_list, path_list = append_path_name(
path, name_list, path_list, False)
2. Inicie un ciclo for utilizando el método os.listdir(ruta) que devuelve una lista de archivos y nombres de carpetas presentes en la ruta actual.
for curr_name in os.listdir(path):
3. Unir el nombre de la carpeta o archivo con la ruta actual.
curr_path = os.path.join(path, curr_name)
4. Si la ruta actual es un directorio, la función se llama a sí misma para recorrer recursivamente las carpetas y almacenar los nombres de las carpetas y las rutas del paso 1.
if os.path.isdir(curr_path) == True: find_using_listdir(curr_path, name_list, path_list)
5. De lo contrario, los nombres de archivo y las rutas se almacenan en name_list y path_list respectivamente.
name_list.append(curr_name) path_list.append(curr_path)
Código para la función mencionada anteriormente:
Python3
import os
# This Function uses os.listdir method to traverse
# folders recursively and appends the name and path of
# file/folders in name_list and path_list respectively.
def find_using_listdir(path, name_list, path_list):
# Function appends folder name and folder path to
# name_list and path_list respectively.
name_list, path_list = append_path_name(path,
name_list, path_list, False)
for curr_name in os.listdir(path):
curr_path = os.path.join(path, curr_name)
# Checks if the current path is a directory.
if os.path.isdir(curr_path) == True:
# If the current path is a directory then the
# function calls itself with the directory path
# and goes on until a file is found
find_using_listdir(curr_path, name_list, path_list)
else:
# Appends file name and file path to
# name_list and path_list respectively.
name_list.append(curr_name)
path_list.append(curr_path)
return name_list, path_list
name_list, path_list = find_using_listdir("/content/sample_data", [], [])
print(name_list)
print(path_list)
Producción:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Método 5: Uso de find_using_glob(ruta, lista_de_nombres, lista_de_rutas)
Esta función devuelve un iterador que produce los mismos valores que glob() sin almacenarlos todos simultáneamente.
Sintaxis: glob.iglob( ruta, recursivo=Verdadero )
Acercarse:
1. Llame a la función append_path_name para almacenar el nombre y la ruta del directorio principal y también devolver la ruta modificada requerida para el método glob ya que el último parámetro es True.
path, name_list, path_list = append_path_name(
path, name_list, path_list, True)
2. Inicie un ciclo for usando el método glob.iglob(path, recursive=True) que recorre recursivamente las carpetas y devuelve la ruta actual del archivo/carpeta.
for curr_path in glob.iglob(path, recursive=True):
3. Llame a la función append_path_name para almacenar los nombres y rutas de archivos/carpetas pasando la ruta actual.
name_list, path_list = append_path_name( curr_path, name_list, path_list, False)
Código para la función mencionada anteriormente:
Python3
import glob
# This Function uses glob.iglob method to traverse
# folders recursively and appends the name and path of
# file/folders in name_list and path_list respectively.
def find_using_glob(path, name_list, path_list):
# Appends the Parent Directory name and path
# and modifies the parent path so that iglob
# can traverse recursively.
path, name_list, path_list = append_path_name(
path, name_list, path_list, True)
# glob.iglob with recursive set to True will
# get all the file/folder paths.
for curr_path in glob.iglob(path, recursive=True):
# Appends file/folder name and path to
# name_list and path_list respectively.
name_list, path_list = append_path_name(
curr_path, name_list, path_list, False)
return name_list, path_list
name_list, path_list = find_using_glob("/content/sample_data", [], [])
print(name_list)
print(path_list)
Producción:
[‘sample_data’, ‘anscombe.json’, ‘california_housing_train.csv’, ‘F2’, ‘SF2’, ‘california_housing_test.csv’,
‘.ipynb_checkpoints’, ‘.ipynb_checkpoints’, ‘F1’, ‘mnist_test.csv’, ‘README.md’, ‘.ipynb_checkpoints’, ‘SF1’,
‘mnist_train_small.csv’]
[‘/content/sample_data’, ‘/content/sample_data/anscombe.json’,
‘/content/sample_data/california_housing_train.csv’, ‘/content/sample_data/F2’,
‘/content/sample_data/F2/SF2’, ‘/content/sample_data/F2/SF2/california_housing_test.csv’,
‘/content/sample_data/F2/.ipynb_checkpoints’, ‘/content/sample_data/.ipynb_checkpoints’,
‘/content/sample_data/F1’, ‘/content/sample_data/F1/mnist_test.csv’, ‘/content/sample_data/F1/README.md’,
‘/content/sample_data/F1/.ipynb_checkpoints’, ‘/content/sample_data/F1/SF1’,
‘/content/sample_data/F1/SF1/mnist_train_small.csv’]
Almacenamiento de datos en la hoja de Excel
Método 1: Usar openpyxl
Este módulo se utiliza para leer/escribir datos en excel. Tiene una amplia gama de características, pero aquí lo usaremos solo para crear y escribir datos para sobresalir. Debe instalar openpyxl a través de pip en su sistema.
pip install openpyxl
Acercarse:
1. Importar los módulos requeridos
# imports workbook from openpyxl module from openpyxl import Workbook
2. Crear un objeto de libro de trabajo
work_book = Workbook()
3. Obtenga el objeto de hoja activa del libro de trabajo e inicie las siguientes variables con 0.
row, col1_width, col2_width = 0, 0, 0 work_sheet = work_book.active
4. Iterar las filas hasta la longitud máxima de name_list ya que estas muchas entradas se escribirán en la hoja de Excel
while row <= len(name_list):
5. Obtenga los objetos de celda de la columna 1 y la columna 2 de la misma fila y almacene los valores de name_list y path_list en las respectivas celdas.
name = work_sheet.cell(row=row+1, column=1)
path = work_sheet.cell(row=row+1, column=2)
# This block will execute only once and
# add the Heading of column 1 and column 2
if row == 0:
name.value = "Name"
path.value = "Path"
row += 1
continue
# Storing the values from name_list and path_list
# to the specified cell objects
name.value = name_list[row-1]
path.value = path_list[row-1]
6. (Opcional) Ajustar el ancho de las celdas en la hoja de Excel usando las dimensiones de columna de openpyxl.
col1_width = max(col1_width, len(name_list[row-1])) col2_width = max(col2_width, len(path_list[row-1])) work_sheet.column_dimensions["A"].width = col1_width work_sheet.column_dimensions["B"].width = col2_width
7. Guarde el libro de trabajo con un nombre de archivo después de que termine la iteración con un nombre de archivo.
work_book.save(filename="Final.xlsx")
Ejemplo:
Python3
# Function will create an excel file and # write the file/ folder names and their # path using openpyxl def create_excel_using_openpyxl(name_list, path_list, path): # Creates a workbook object and gets an # active sheet work_book = Workbook() work_sheet = work_book.active # Writing the data in excel sheet row, col1_width, col2_width = 0, 0, 0 while row <= len(name_list): name = work_sheet.cell(row=row+1, column=1) path = work_sheet.cell(row=row+1, column=2) # Writing the Heading i.e Name and Path if row == 0: name.value = "Name" path.value = "Path" row += 1 continue # Writing the data from specified lists to columns name.value = name_list[row-1] path.value = path_list[row-1] # Adjusting width of Column in excel sheet col1_width = max(col1_width, len(name_list[row-1])) col2_width = max(col2_width, len(path_list[row-1])) work_sheet.column_dimensions["A"].width = col1_width work_sheet.column_dimensions["B"].width = col2_width row += 1 # Saving the workbook work_book.save(filename="Final.xlsx") create_excel_using_openpyxl(name_list, path_list, path)
Producción:
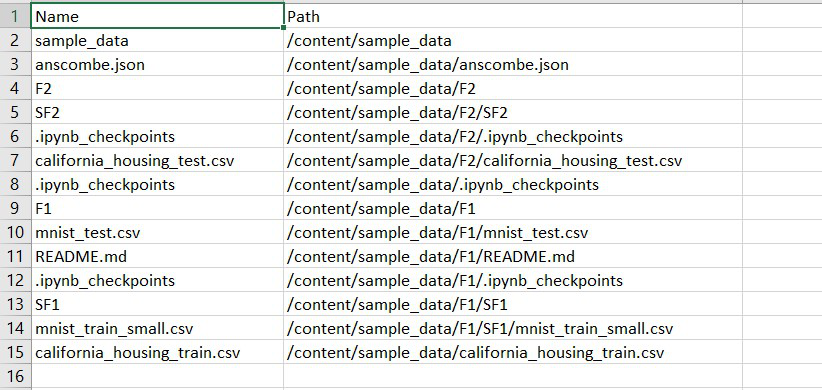
Método 2: Usar pandas
1. Cree un cuadro (un diccionario) con las claves ‘Nombre’ y ‘Ruta’ y valores como lista_nombre y lista_ruta respectivamente:
frame = {'Name': name_list,
'Path': path_list
}
2. Antes de exportar, debemos crear un marco de datos llamado df_data con columnas como Nombre y Ruta.
df_data = pd.DataFrame(frame)
3. Exporte los datos a Excel usando el siguiente código:
df_data.to_excel('Final.xlsx', index=False)
Código para la función mencionada anteriormente:
Python3
# Function will create a data frame using pandas and
# write File/Folder, and their path to excel file.
def create_excel_using_pandas_dataframe(name_list,
path_list, path):
# Default Frame (a dictionary) is created with
# File/Folder names and their path with the given lists
frame = {'Name': name_list,
'Path': path_list
}
# Creates the dataframe using pandas with the given
# dictionary
df_data = pd.DataFrame(frame)
# Creates and saves the data to an excel file
df_data.to_excel('Final.xlsx', index=False)
create_excel_using_pandas_dataframe(name_list,
path_list, path)
Producción:
Publicación traducida automáticamente
Artículo escrito por anilabhadatta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA