En este artículo, aprenderemos cómo crear múltiples archivos CSV a partir de un archivo CSV existente usando Pandas. Cuando ingresemos nuestro código en producción, tendremos que lidiar con la edición de nuestros archivos de datos. Debido al gran tamaño del archivo de datos, encontraremos más problemas, por lo que dividimos este archivo en algunos archivos pequeños según algunos criterios, como dividir en filas, columnas, valores específicos de columnas, etc.
Primero, creemos un archivo CSV simple y usémoslo para todos los ejemplos a continuación en el artículo. Cree un conjunto de datos utilizando el método de marco de datos de pandas y luego guárdelo en el archivo «Customers.csv» o podemos cargar el conjunto de datos existente con la función pandas read_csv().
Python3
import pandas as pd
# initialise data dictionary.
data_dict = {'CustomerID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'Gender': ["Male", "Female", "Female", "Male",
"Male", "Female", "Male", "Male",
"Female", "Male"],
'Age': [20, 21, 19, 18, 25, 26, 32, 41, 20, 19],
'Annual Income(k$)': [10, 20, 30, 10, 25, 60, 70,
15, 21, 22],
'Spending Score': [30, 50, 48, 84, 90, 65, 32, 46,
12, 56]}
# Create DataFrame
data = pd.DataFrame(data_dict)
# Write to CSV file
data.to_csv("Customers.csv")
# Print the output.
print(data)
Producción:
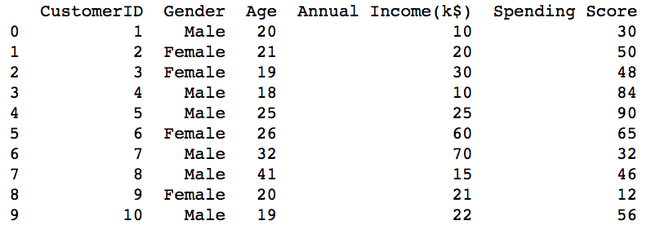
Creación de varios archivos CSV a partir del archivo CSV existente
Para hacer nuestro trabajo, discutiremos diferentes métodos que son los siguientes:
Método 1: división basada en filas
En este método, dividiremos un archivo CSV en varios CSV en función de las filas.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
# no of csv files with row size
k = 2
size = 5
for i in range(k):
df = data[size*i:size*(i+1)]
df.to_csv(f'Customers_{i+1}.csv', index=False)
df_1 = pd.read_csv("Customers_1.csv")
print(df_1)
df_2 = pd.read_csv("Customers_2.csv")
print(df_2)
Producción:
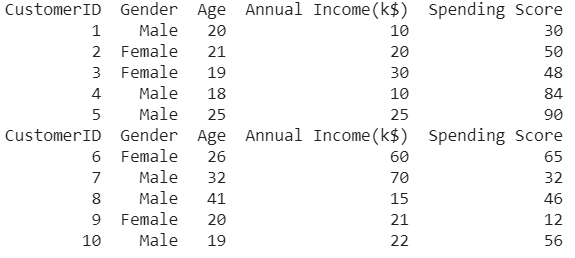
Método 2: División basada en columnas
Ejemplo 1:
Usando el método groupby() de Pandas podemos crear múltiples archivos CSV. Para crear un archivo podemos usar el método to_csv() de Pandas. Aquí se crearon dos archivos basados en los valores «masculino» y «femenino» de las columnas Género.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
for (gender), group in data.groupby(['Gender']):
group.to_csv(f'{gender}.csv', index=False)
print(pd.read_csv("Male.csv"))
print(pd.read_csv("Female.csv"))
Producción:
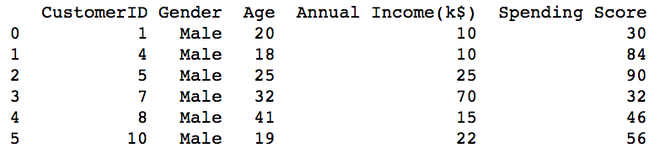
Hombre.csv
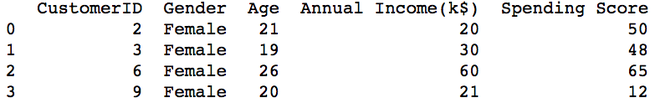
Femenino.csv
Ejemplo 2:
Podemos agrupar más de dos columnas y podemos crear varios archivos sobre la base de una combinación de valores únicos del valor de ambas columnas. Tome las columnas Género e Ingreso anual.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
for (Gender, Income), group in data.groupby(['Gender', 'Annual Income(k$)']):
group.to_csv(f'{Gender} {Income}.csv', index=False)
print(pd.read_csv(f'{Gender} {Income}.csv'))
Producción:
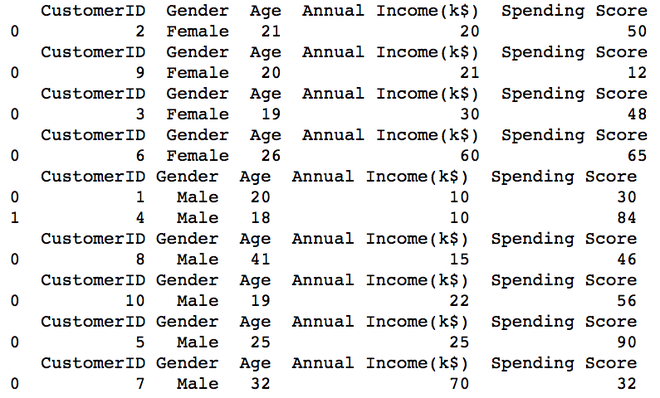
Los nueve archivos CSV
Ejemplo 3:
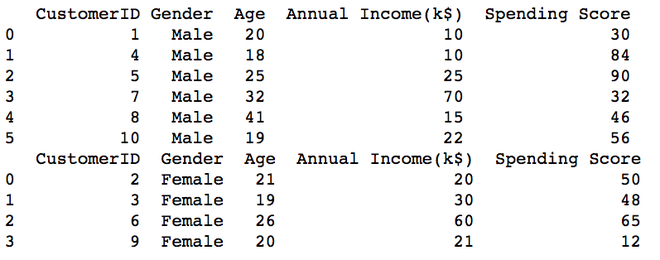
Filtraremos las columnas en función del nombre de columna específico Género a sus valores (Masculino y Femenino). Luego conviértalo a un archivo CSV usando to_csv en pandas.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
male = data[data['Gender'] == 'Male']
female = data[data['Gender'] == 'Female']
male.to_csv('Gender_male.csv', index=False)
female.to_csv('Gender_female.csv', index=False)
print(pd.read_csv("Gender_male.csv"))
print(pd.read_csv("Gender_female.csv"))
Producción:
Método 3: división basada tanto en filas como en columnas
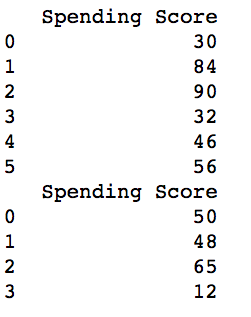
Usando el método groupby() de Pandas, podemos crear múltiples archivos CSV por filas. Para crear un archivo podemos usar el método to_csv() de Pandas. Aquí se crearon dos archivos basados en los valores de fila «masculino» y «femenino» de la columna de género específica para el puntaje de gasto.
Python3
for (gender), group in data['Spending Score'].groupby(data['Gender']):
group.to_csv(f'{gender}Score.csv', index=False)
print(pd.read_csv("MaleScore.csv"))
print(pd.read_csv("FemaleScore.csv"))
Producción:
Publicación traducida automáticamente
Artículo escrito por dangarenitesh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA