Requisito previo: expresión regular en Python
En este artículo, veremos cómo eliminar caracteres que se repiten continuamente de las palabras de la columna dada del Dataframe de Pandas dado usando Regex.
Aquí, en realidad estamos buscando caracteres que se presenten de manera repetitiva y que ocurran continuamente, por lo que hemos creado un patrón que contiene esta expresión regular (\w)\1+ aquí \w es para el carácter, 1+ es para los caracteres que aparecen más de una vez.
Estamos pasando nuestro patrón en la función re.sub() de la biblioteca re.
Sintaxis: re.sub(patrón, repl, string, cuenta=0, banderas=0)
El ‘sub’ en la función significa SubString, se busca un cierto patrón de expresión regular en la string dada (tercer parámetro), y al encontrar el patrón de substring se reemplaza por repl (segundo parámetro), el conteo verifica y mantiene el número de veces esto ocurre.
Ahora, vamos a crear un marco de datos:
Python3
# importing required libraries
import pandas as pd
import re
# creating Dataframe with column
# as name and common_comments
df = pd.DataFrame(
{
'name' : ['Akash', 'Ayush', 'Diksha',
'Priyanka', 'Radhika'],
'common_comments' : ['hey buddy meet me today ',
'sorry bro i cant meet',
'hey akash i love geeksforgeeks',
'twiiter is the best way to comment',
'geeksforgeeks is good for learners']
},
columns = ['name', 'common_comments']
)
# printing Dataframe
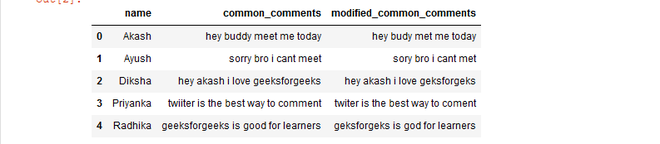
df
Producción:

Ahora, elimine los caracteres continuamente repetitivos de las palabras de la columna Common_comments del marco de datos.
Python3
# define a function to remove # continuously repeating character # from the word def conti_rep_char(str1): tchr = str1.group(0) if len(tchr) > 1: return tchr[0:1] # define a function to check # whether unique character # is present or not def check_unique_char(rep, sent_text): # regular expression for # repetition of characters convert = re.sub(r'(\w)\1+', rep, sent_text) # returning the converted word return convert df['modified_common_comments'] = df['common_comments'].apply( lambda x : check_unique_char(conti_rep_char, x)) # show Dataframe df
Producción: