En este artículo, discutiremos cómo eliminar filas con algunos o todos los NA en el lenguaje de programación R.
Consideraremos un marco de datos y luego eliminaremos filas en R. Vamos a crear un marco de datos con 3 columnas y 6 filas.
R
# create dataframe
data = data.frame(names=c("manoj", "bobby", "sravan", "deepu", NA, NA),
id=c(1, 2, 3, NA, NA, NA),
subjects=c("java", "python", NA, NA, "java", "python"))
# display
print(data)
Salida :
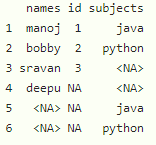
Método 1: Eliminación de filas con algunas NA utilizando la función na.omit()
Aquí esta función eliminará todas las filas que contengan NA.
Sintaxis :
na.omit(dataframe)
donde, marco de datos es el marco de datos de entrada.
Ejemplo :
R
# create dataframe
data = data.frame(names=c("manoj", "bobby", "sravan", "deepu", NA, NA),
id=c(1, 2, 3, NA, NA, NA),
subjects=c("java", "python", NA, NA, "java", "python"))
# remove NA's in entire dataframe
print(na.omit(data))
Salida :
names id subjects 1 manoj 1 java 2 bobby 2 python
Método 2: eliminar filas con algunas NA utilizando la función complete.cases()
Aquí, esta función eliminará los NA en el marco de datos.
Sintaxis :
dataframe[complete.cases(dataframe), ]
Ejemplo :
R
# create dataframe
data = data.frame(names=c("manoj", "bobby", "sravan", "deepu", NA, NA),
id=c(1, 2, 3, NA, NA, NA),
subjects=c("java", "python", NA, NA, "java", "python"))
# remove NA's in entire dataframe
print(data[complete.cases(data), ])
Salida :
names id subjects 1 manoj 1 java 2 bobby 2 python
Método 3: eliminar filas con algunas NA utilizando las funciones rowSums() e is.na()
Aquí estamos verificando la suma de filas a 0, luego consideraremos el NA y luego los eliminaremos.
Sintaxis :
data[rowSums(is.na(data)) == 0, ]
donde, datos es el marco de datos de entrada
Ejemplo :
R
# create dataframe
data = data.frame(names=c("manoj", "bobby", "sravan", "deepu", NA, NA),
id=c(1, 2, 3, NA, NA, NA),
subjects=c("java", "python", NA, NA, "java", "python"))
# remove NA's in entire dataframe
print(data[rowSums(is.na(data)) == 0, ])
Salida :
names id subjects 1 manoj 1 java 2 bobby 2 python
Método 4: Eliminación de filas con algunas NA usando la función drop_na() del paquete tidyr
Aquí vamos a eliminar las filas con NA usando la función drop_na(). Antes de eso, tenemos que cargar la biblioteca tidyr.
Sintaxis :
data %>% drop_na()
donde, datos es el marco de datos de entrada
Ejemplo :
R
# load the dplyr package
library("tidyr")
# create dataframe
data = data.frame(names=c("manoj", "bobby", "sravan", "deepu", NA, NA),
id=c(1, 2, 3, NA, NA, NA),
subjects=c("java", "python", NA, NA, "java", "python"))
# remove NA's in entire dataframe
print(data % > % drop_na())
Salida :
names id subjects 1 manoj 1 java 2 bobby 2 python
Publicación traducida automáticamente
Artículo escrito por manojkumarreddymallidi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA