NaN significa Not A Number y es una de las formas comunes de representar el valor que falta en los datos. Es un valor de punto flotante especial y no se puede convertir a ningún otro tipo que no sea flotante. El valor de NaN es uno de los principales problemas en el análisis de datos. Es muy esencial tratar con NaN para obtener los resultados deseados. En este artículo, discutiremos cómo soltar filas con valores NaN.
Podemos eliminar filas que tienen valores NaN en Pandas DataFrame usando la función dropna()
df.dropna()
También es posible eliminar filas con valores NaN con respecto a columnas particulares usando la siguiente declaración:
df.dropna(subset, inplace=True)
Con el conjunto establecido en True y el subconjunto establecido en una lista de nombres de columnas para colocar todas las filas con NaN debajo de esas columnas.
Ejemplo 1:
Python3
# importing libraries
import pandas as pd
import numpy as np
num = {'Integers': [10, 15, 30, 40, 55, np.nan,
75, np.nan, 90, 150, np.nan]}
# Create the dataframe
df = pd.DataFrame(num, columns =['Integers'])
# dropping the rows having NaN values
df = df.dropna()
# printing the result
df
Producción:
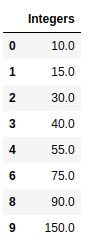
Nota: También podemos restablecer los índices usando el método reset_index()
df = df.reset_index(drop=True)
Ejemplo 2:
Python3
# importing libraries
import pandas as pd
import numpy as np
nums = {'Integers_1': [10, 15, 30, 40, 55, np.nan,
75, np.nan, 90, 150, np.nan],
'Integers_2': [np.nan, 21, 22, 23, np.nan,
24, 25, np.nan, 26, np.nan,
np.nan]}
# Create the dataframe
df = pd.DataFrame(nums, columns =['Integers_1', 'Integers_2'])
# dropping the rows having NaN values
df = df.dropna()
# To reset the indices
df = df.reset_index(drop = True)
# Print the dataframe
df
Producción:
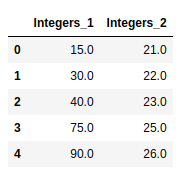
Ejemplo 3:
Python3
# importing libraries
import pandas as pd
import numpy as np
nums = {'Student Number': [ 1001, 1111, 1202, 1229, 1330,
1335, np.nan, 1400, 1150, np.nan],
'Seat Number': [np.nan, 15, 22, 43, np.nan, 44,
55, np.nan, 57, np.nan]}
# Create the dataframe
df = pd.DataFrame(nums, columns =['Student Number', 'Seat Number'])
# dropping the rows having NaN values
df = df.dropna()
# To reset the indices
df = df.reset_index(drop = True)
# Print the dataframe
df
Producción:
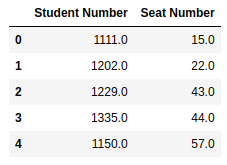
Ejemplo 4:
Python3
# importing libraries
import pandas as pd
import numpy as np
car = {'Year of Launch': [ 1999, np.nan, 1986, 2020, np.nan,
1991, 2007, 2011, 2001, 2017],
'Engine Number': [np.nan, 15, 22, 43, 44, np.nan,
55, np.nan, 57, np.nan],
'Chasis Unique Id': [4023, np.nan, 3115, 4522, 3643,
3774, 2955, np.nan, 3587, np.nan]}
# Create the dataframe
df = pd.DataFrame(car, columns =['Year of Launch', 'Engine Number',
'Chasis Unique Id'])
# dropping the rows having NaN values
df = df.dropna()
# To reset the indices
df = df.reset_index(drop = True)
# Print the dataframe
df
Producción:
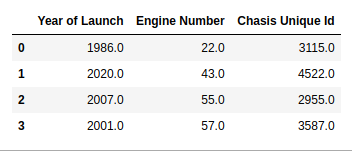
Ejemplo 5:
Python3
# Importing libraries
import pandas as pd
import numpy as np
# Creating a dictionary
dit = {'August': [10, np.nan, 34, 4.85, 71.2, 1.1],
'September': [np.nan, 54, 68, 9.25, pd.NaT, 0.9],
'October': [np.nan, 5.8, 8.52, np.nan, 1.6, 11],
'November': [pd.NaT, 5.8, 50, 8.9, 77, pd.NaT]}
# Converting it to data frame
df = pd.DataFrame(data=dit)
# Dropping the rows having NaN/NaT values
# when threshold of nan values is 2
df = df.dropna(thresh=2)
# Resetting the indices using df.reset_index()
df = df.reset_index(drop=True)
df
Producción:
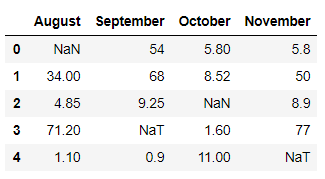
En el ejemplo anterior, usamos thresh = 2 dentro de la función df.dropna(), lo que significa que descartará todas aquellas filas donde los valores de Nan/NaT sean 2 o más de 2, otras permanecerán como están.
Ejemplo 6:
Python3
# Importing libraries
import pandas as pd
import numpy as np
# Creating a dictionary
dit = {'August': [10, np.nan, 34, 4.85, 71.2, 1.1],
'September': [np.nan, 54, 68, 9.25, pd.NaT, 0.9],
'October': [np.nan, 5.8, 8.52, np.nan, 1.6, 11],
'November': [pd.NaT, 5.8, 50, 8.9, 77, pd.NaT]}
# Converting it to data frame
df = pd.DataFrame(data=dit)
# Dropping the rowns having NaN/NaT values
# under certain label
df = df.dropna(subset=['October'])
# Resetting the indices using df.reset_index()
df = df.reset_index(drop=True)
df
Producción:
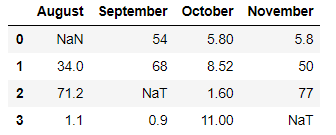
En el ejemplo anterior, usamos subconjunto = [‘Octubre’] dentro de la función df.dropna(), lo que significa que eliminará todas las filas que tengan valores Nan/NaT bajo la etiqueta ‘Octubre’.
Publicación traducida automáticamente
Artículo escrito por shardul_singh_tomar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA