Prerrequisitos: pandas
Uno puede abrir y editar archivos CSV en Python a través de la biblioteca Pandas. Al editar el archivo, es posible que desee eliminar toda la fila del archivo. Los siguientes son algunos enfoques diferentes para hacer lo mismo:
Conjunto de datos en uso: conjunto de datos iris.csv
Método 1: Usar el corte
Este método solo es bueno para eliminar la primera o la última fila del conjunto de datos. Y las siguientes dos líneas de código que, aunque significan lo mismo, representan el uso del método .iloc[] en pandas.
Sintaxis:
df.iloc[<número_fila>, <número_columna>]
o
df.iloc[<número_fila>]
Enfoque: para eliminar la primera fila
- Importar la biblioteca
- Cargue el conjunto de datos en python
- Para eliminar la primera fila usando el corte. Dado que la columna de índice de forma predeterminada es numérica, la etiqueta de índice también será de números enteros.
(Se eliminarán 0 índices ya que en python la indexación comienza desde 0):
Programa:
Python3
import pandas as pd url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv" df = pd.read_csv(url) df = df.iloc[1:] print(df)
Producción
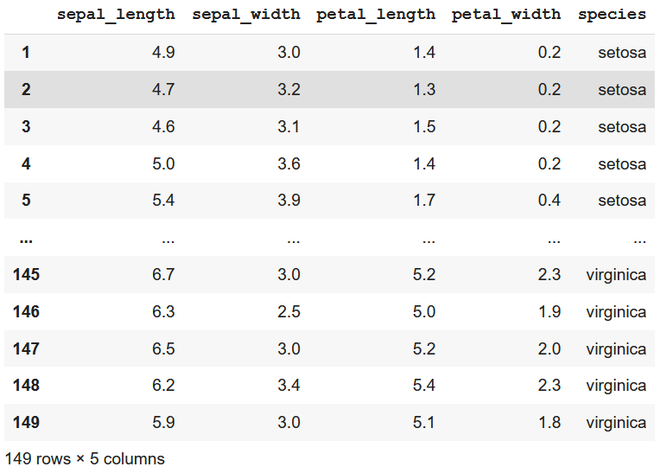
eliminando la primera fila
Enfoque: Para eliminar la última fila
- importar la biblioteca
- cargar el conjunto de datos en python
- para eliminar la última fila usando el corte. Como la columna de índice de forma predeterminada es numérica, la etiqueta de índice también será de números enteros.
(aquí -1 representa la última fila de los datos)
Programa:
Python3
import pandas as pd url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv" df = pd.read_csv(url) df = df.iloc[:-1] print(df)
Producción
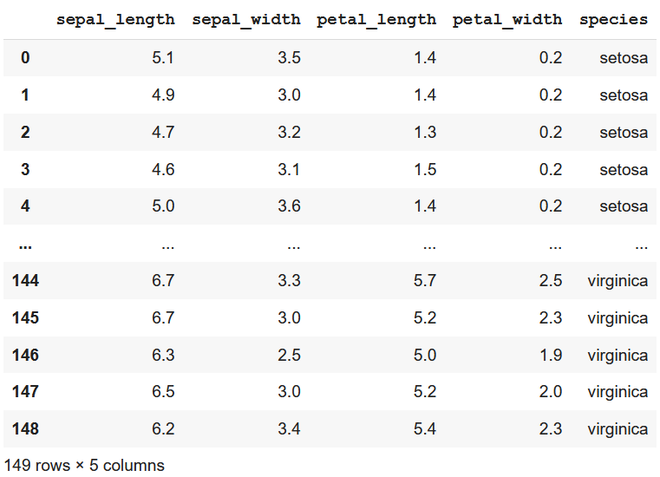
eliminando la última fila
Método 2: Usando el método drop()
Eliminar usando la etiqueta significa que el nombre de la fila se especifica en el código, mientras que usar la indexación significa que el índice (posición/número de fila a partir de 0) de la fila se especifica en el código.
Conjunto de datos en uso:
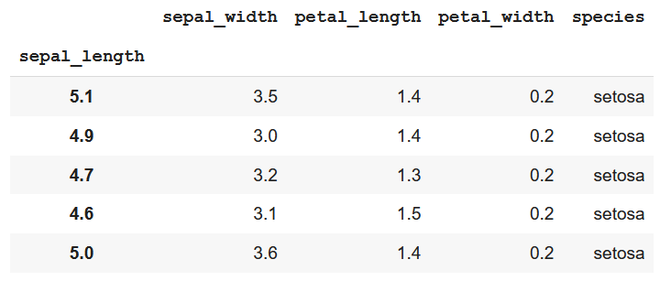
subconjunto: 5 elementos principales
Enfoque: uso de la etiqueta de fila
- Importar biblioteca de pandas
- Cargar conjunto de datos
- Seleccione los datos requeridos
- Con el uso de etiqueta de fila (aquí 5.1) soltando la fila correspondiente a la misma etiqueta. La etiqueta puede ser de cualquier tipo de datos (string, entero, flotante, etc.).
Programa:
Python3
import pandas as pd
url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv"
df = pd.read_csv(url)
# 2.
df_s = df[:5]
# 3.
df_s.set_index('sepal_length', inplace=True)
# 4.1.
df_s = df_s.drop(5.1)
print(df_s)
Producción
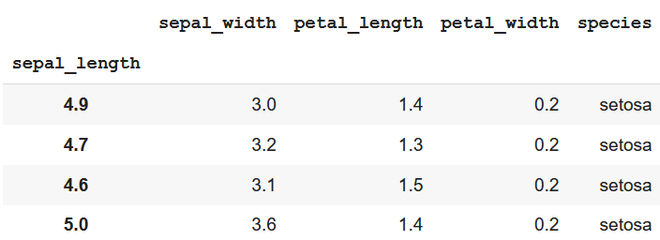
usando la etiqueta de fila
Enfoque: uso del índice de fila
- Importar biblioteca de pandas
- Cargar conjunto de datos
- Seleccione los datos requeridos
- Con el uso del índice de fila, se debe pasar el índice de la fila que se eliminará.
df.index[ ] toma números de índice como parámetro a partir de 1 y en adelante, mientras que en python la indexación comienza desde 0.
Programa:
Python3
import pandas as pd
url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv"
df = pd.read_csv(url)
df_s = df[:5]
df_s.set_index('sepal_length', inplace=True)
df_s = df_s.drop(df_s.index[1])
#df_s.drop(df_s.index[1],inplace = True)
print(df_s)
Producción
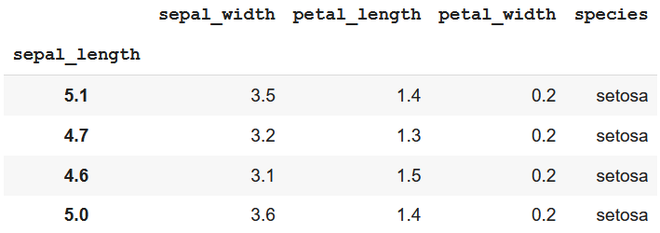
utilizando el índice de fila
Método 3: Eliminar usando Condiciones
Conjunto de datos en uso:
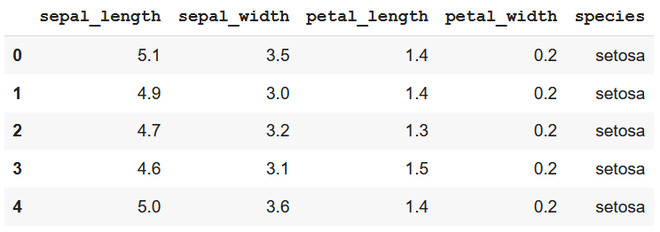
subconjunto: 5 elementos principales
Enfoque 1:
- Módulo de importación
- Cargar datos
- Seleccione los datos requeridos
- Encuentre la fila que especifica la condición especificada
- Use el método drop() y pase el índice de la fila obtenida como parámetro en el método drop.
Programa:
Python3
import pandas as pd url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv" df = pd.read_csv(url) df_s1 = df[:5] df_s1 = df_s1.drop(df_s1[(df_s1.sepal_length == 4.7) & (df_s1.petal_length == 1.3)].index) print(df_s1)
Producción
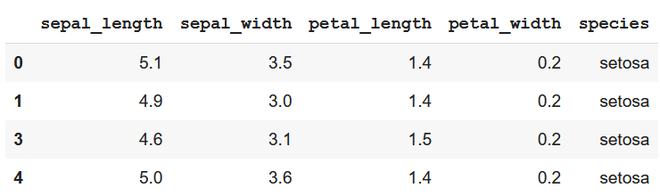
primer método: eliminación condicional
Enfoque 2:
- Módulo de importación
- Cargar datos
- Seleccione los datos requeridos
- Encuentre la fila que especifica la condición especificada usando el método query()
- Use el método drop() y pase el índice de la fila obtenida como parámetro en el método drop.
Programa:
Python3
import pandas as pd
url = "https://gist.githubusercontent.com/curran/a08a1080b88344b0c8a7/raw/0e7a9b0a5d22642a06d3d5b9bcbad9890c8ee534/iris.csv"
df = pd.read_csv(url)
df_s1 = df[:5]
df_s1 = df_s1.drop(df_s1.query('sepal_length==5.0').index)
print(df_s1)
Producción:
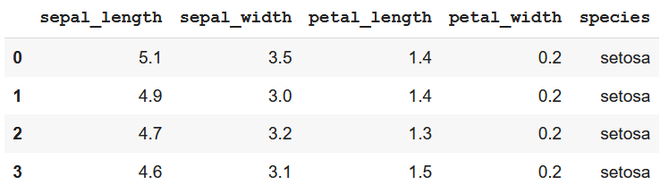
segundo método: eliminación condicional
Publicación traducida automáticamente
Artículo escrito por rajeshsharma7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA