Encontrar estadísticas de resumen grupales para el marco de datos es muy útil para comprender nuestro marco de datos. El resumen incluye datos estadísticos: media, mediana, mín., máx. y cuartiles del marco de datos dado. El resumen se puede calcular en una sola columna o variable, o en todo el marco de datos. En este artículo, veremos cómo encontrar estadísticas de resumen grupales para el marco de datos en el lenguaje de programación R.
Importación de datos en lenguaje R
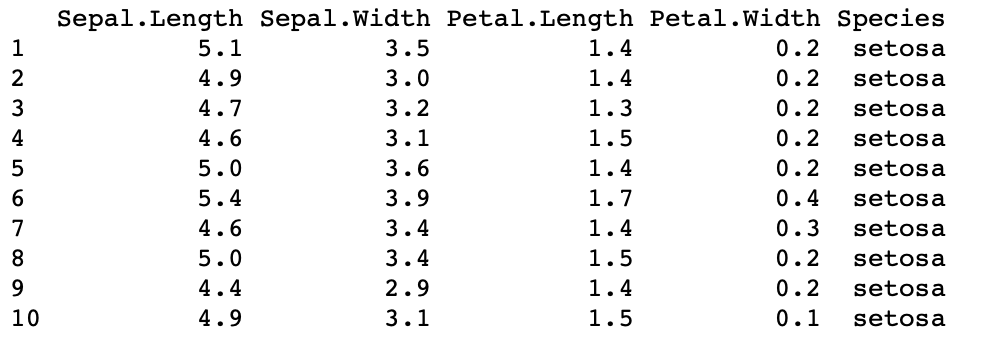
En el siguiente código, hemos utilizado un conjunto de datos incorporado: conjunto de datos de flores de iris. Luego podemos inspeccionar nuestro conjunto de datos usando la función head() o tail() que imprimirá la parte superior e inferior del marco de datos. En el código a continuación, hemos mostrado las 10 filas superiores de nuestro marco de datos de muestra.
R
# import data df <- iris # inspecting the dataset head(df, 10)
Producción:
Resumen de una sola variable o columna
Nuestro marco de datos se almacena en la variable » df «. Queremos imprimir el resumen de la columna: Sepal.Length. Por lo tanto, pasamos «df$Sepal.length» como argumento en la función de resumen().
Sintaxis: resumen (marco de datos $nombre_columna)
La función summary() toma una columna de marco de datos y devuelve:
- Tendencia central-> media y mediana,
- Rango intercuartílico-> cuartiles 25 y 75,
- Rango-> valores mínimos y máximos para esa sola columna.
Ejemplo 1:
R
df <- iris summary(df$Sepal.Length)
Producción:

Ejemplo 2: También podemos pasar los » dígitos » como un argumento que especifica hasta cuántos lugares decimales queremos corregir nuestros valores de salida
Sintaxis: resumen (marco de datos $nombre_columna, dígitos = número_de_lugares_decimales)
R
df <- iris summary(df$Sepal.Width, digits = 3)
Producción:
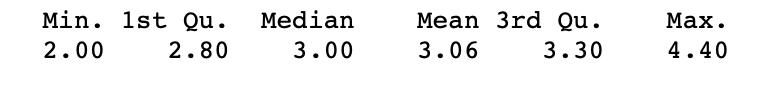
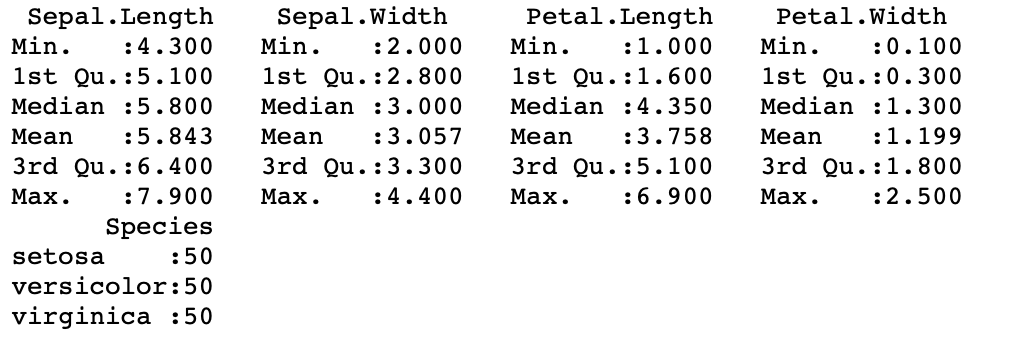
Resumen de todo el marco de datos
En el siguiente código, hemos pasado el marco de datos completo como argumento en la función de resumen() , por lo que calcula un resumen del marco de datos completo (todas las columnas o variables)
Sintaxis: resumen (nombre del marco de datos)
R
df <- iris summary(df)
Producción:
Resumen de datos por grupos
Para una mejor comprensión de Dataframe en R, se recomienda consultar el artículo R – Data Frames .
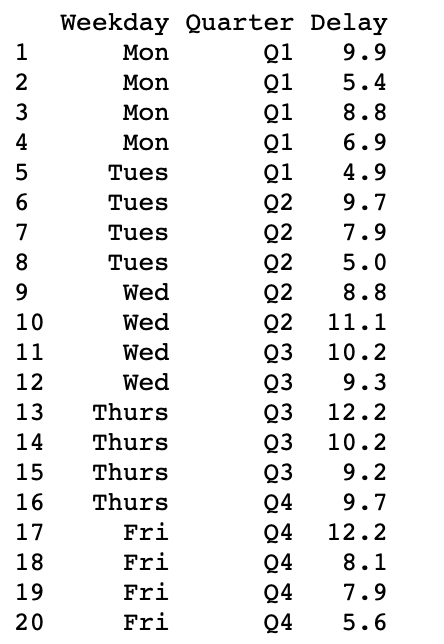
Primero creemos un marco de datos de muestra:
R
df <- data.frame(
Weekday = factor(rep(c("Mon", "Tues", "Wed",
"Thurs", "Fri"), each = 4),
levels = c("Mon", "Tues", "Wed",
"Thurs", "Fri")),
Quarter = paste0("Q", rep(1:4, each = 5)),
Delay = c(9.9, 5.4, 8.8, 6.9, 4.9, 9.7, 7.9, 5, 8.8,
11.1, 10.2, 9.3, 12.2, 10.2, 9.2, 9.7, 12.2,
8.1, 7.9, 5.6))
df
Producción:
Resumen de datos grupales de variable única
Nuestro marco de datos consta de 3 variables: Día de la semana , Trimestre y Retraso . La variable que resumiremos es Retraso y, en el proceso , la variable Trimestre se contraerá.
En el siguiente código, usaremos el paquete dplyr . El paquete dplyr en R es una estructura de manipulación de datos que proporciona un conjunto uniforme de verbos, lo que ayuda a resolver los obstáculos de manipulación de datos más frecuentes. Realizaremos una operación de agrupación usando la función group_by() y una operación de resumen usando la función resume() . Luego calcularemos 2 resúmenes estadísticos: tiempo máximo de demora y tiempo mínimo de demora.
Sintaxis: group_by(nombre_variable)
R
library(dplyr)
df <- data.frame(
Weekday = factor(rep(c("Mon", "Tues", "Wed", "Thurs",
"Fri"), each = 4),
levels = c("Mon", "Tues", "Wed", "Thurs",
"Fri")),
Quarter = paste0("Q", rep(1:4, each = 5)),
Delay = c(9.9, 5.4, 8.8, 6.9, 4.9, 9.7, 7.9, 5, 8.8,
11.1, 10.2, 9.3, 12.2, 10.2, 9.2, 9.7, 12.2,
8.1, 7.9, 5.6))
df %>%
group_by(Weekday) %>%
summarize(min_delay = min(Delay), max_delay = max(Delay))
Producción:

Resumen de datos grupales de variable múltiple
Vamos a crear otro marco de datos de muestra ->df2:
R
# sample dataframe
df2 <- data.frame(
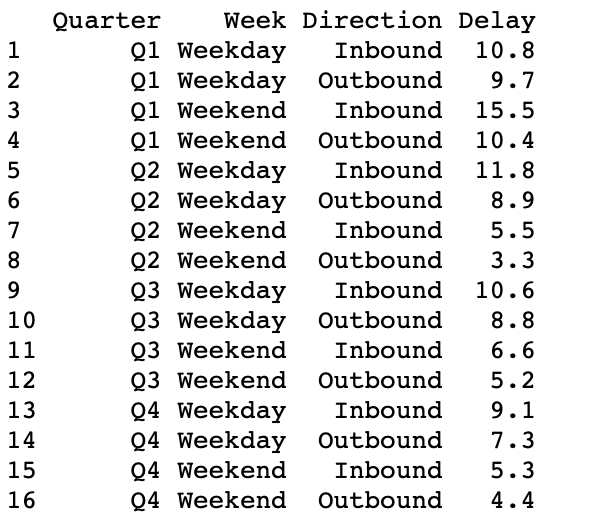
Quarter = paste0("Q", rep(1:4, each = 4)),
Week = rep(c("Weekday", "Weekend"), each=2, times=4),
Direction = rep(c("Inbound", "Outbound"), times=8),
Delay = c(10.8, 9.7, 15.5, 10.4, 11.8, 8.9, 5.5,
3.3, 10.6, 8.8, 6.6, 5.2, 9.1, 7.3, 5.3, 4.4))
df2
Producción:
Resumiendo los datos por grupos:
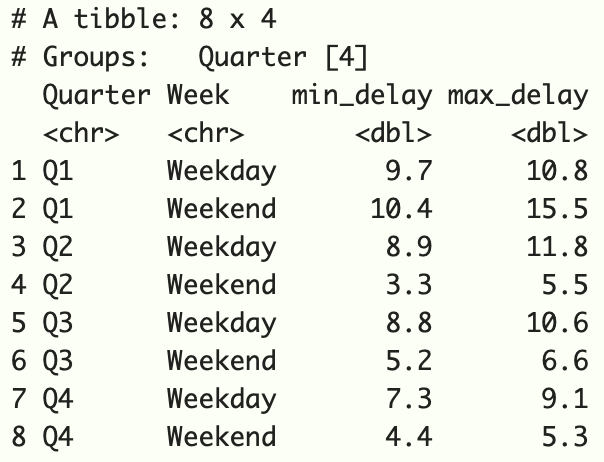
En este caso, nuestro marco de datos tiene 4 variables: Trimestre, Semana, Dirección, Retraso . En el siguiente código, hemos agrupado y resumido por Trimestre y Semana y, en el proceso, la variable Dirección se colapsa.
Sintaxis: group_by(variable_name1,variable_name2 )
R
library(dplyr)
# sample dataframe
df2 <- data.frame(
Quarter = paste0("Q", rep(1:4, each = 4)),
Week = rep(c("Weekday", "Weekend"), each=2, times=4),
Direction = rep(c("Inbound", "Outbound"), times=8),
Delay = c(10.8, 9.7, 15.5, 10.4, 11.8, 8.9, 5.5,
3.3, 10.6, 8.8, 6.6, 5.2, 9.1, 7.3, 5.3, 4.4))
# summarizing by group
df2 %>%
group_by(Quarter, Week) %>%
summarize(min_delay = min(Delay), max_delay = max(Delay))
Salida :
Publicación traducida automáticamente
Artículo escrito por sudhanshublaze y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA