Encontrar los 10 o 20 registros principales de un gran conjunto de datos es el corazón de muchos sistemas de recomendación y también es un atributo importante para el análisis de datos. Aquí, discutiremos los dos métodos para encontrar registros top-N de la siguiente manera.
Método 1: Primero, busquemos las 10 películas más vistas para entender los métodos y luego lo generalizaremos para ‘n’ registros.
Formato de datos:
movie_name and no_of_views (tab separated)
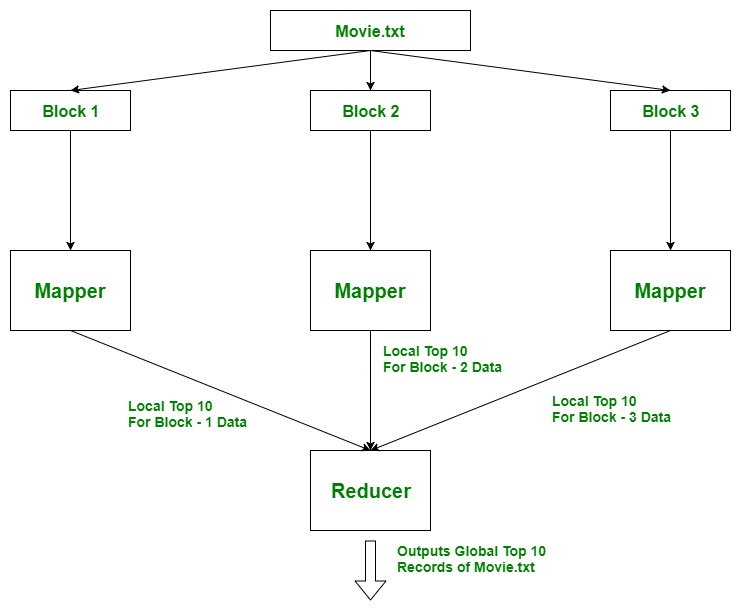
Enfoque utilizado: uso de TreeMap. Aquí, la idea es usar Mappers para encontrar los 10 mejores registros locales , ya que puede haber muchos Mappers ejecutándose en paralelo en diferentes bloques de datos de un archivo. Y luego todos estos 10 registros principales locales se agregarán en Reducer, donde encontramos los 10 registros globales principales para el archivo.
Ejemplo: suponga que el archivo (30 TB) se divide en 3 bloques de 10 TB cada uno y cada bloque es procesado por un Mapeador en forma paralela, por lo que encontramos los 10 registros principales (locales) para ese bloque. Luego, estos datos se mueven al reductor donde encontramos los 10 registros principales reales del archivo movie.txt .
Archivo Movie.txt: Puede ver el archivo completo haciendo clic aquí

Código del mapeador:
Java
import java.io.*;
import java.util.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
public class top_10_Movies_Mapper extends Mapper<Object,
Text, Text, LongWritable> {
private TreeMap<Long, String> tmap;
@Override
public void setup(Context context) throws IOException,
InterruptedException
{
tmap = new TreeMap<Long, String>();
}
@Override
public void map(Object key, Text value,
Context context) throws IOException,
InterruptedException
{
// input data format => movie_name
// no_of_views (tab separated)
// we split the input data
String[] tokens = value.toString().split("\t");
String movie_name = tokens[0];
long no_of_views = Long.parseLong(tokens[1]);
// insert data into treeMap,
// we want top 10 viewed movies
// so we pass no_of_views as key
tmap.put(no_of_views, movie_name);
// we remove the first key-value
// if it's size increases 10
if (tmap.size() > 10)
{
tmap.remove(tmap.firstKey());
}
}
@Override
public void cleanup(Context context) throws IOException,
InterruptedException
{
for (Map.Entry<Long, String> entry : tmap.entrySet())
{
long count = entry.getKey();
String name = entry.getValue();
context.write(new Text(name), new LongWritable(count));
}
}
}
Explicación: El punto importante a tener en cuenta aquí es que usamos » context.write() » en el método cleanup() que se ejecuta solo una vez al final de la vida útil de Mapper. Mapper procesa un par clave-valor a la vez y los escribe como salida intermedia en el disco local. Pero tenemos que procesar el bloque completo (todos los pares clave-valor) para encontrar top10, antes de escribir el resultado, por lo que usamos context.write() en cleanup().
Código reductor:
Java
import java.io.IOException;
import java.util.Map;
import java.util.TreeMap;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class top_10_Movies_Reducer extends Reducer<Text,
LongWritable, LongWritable, Text> {
private TreeMap<Long, String> tmap2;
@Override
public void setup(Context context) throws IOException,
InterruptedException
{
tmap2 = new TreeMap<Long, String>();
}
@Override
public void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException
{
// input data from mapper
// key values
// movie_name [ count ]
String name = key.toString();
long count = 0;
for (LongWritable val : values)
{
count = val.get();
}
// insert data into treeMap,
// we want top 10 viewed movies
// so we pass count as key
tmap2.put(count, name);
// we remove the first key-value
// if it's size increases 10
if (tmap2.size() > 10)
{
tmap2.remove(tmap2.firstKey());
}
}
@Override
public void cleanup(Context context) throws IOException,
InterruptedException
{
for (Map.Entry<Long, String> entry : tmap2.entrySet())
{
long count = entry.getKey();
String name = entry.getValue();
context.write(new LongWritable(count), new Text(name));
}
}
}
Explicación: Misma lógica que mapeador. Reducer procesa un par clave-valor a la vez y los escribe como salida final en HDFS. Pero tenemos que procesar todos los pares clave-valor para encontrar top10, antes de escribir el resultado, por lo que usamos cleanup() .
Código del conductor:
Java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Driver {
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,
args).getRemainingArgs();
// if less than two paths
// provided will show error
if (otherArgs.length < 2)
{
System.err.println("Error: please provide two paths");
System.exit(2);
}
Job job = Job.getInstance(conf, "top 10");
job.setJarByClass(Driver.class);
job.setMapperClass(top_10_Movies_Mapper.class);
job.setReducerClass(top_10_Movies_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Ejecutando el archivo jar:
- Exportamos todas las clases como archivos jar .
- Movemos nuestro archivo movie.txt del sistema de archivos local a /geeksInput en HDFS.
bin/hdfs dfs -put ../Desktop/movie.txt /geeksInput
- Ahora ejecutamos los servicios de hilo para ejecutar el archivo jar.
bin/yarn jar jar_file_location package_Name.Driver_classname input_path output_path

- Hacemos nuestro parámetro personalizado usando el método set()
configuration_object.set(String name, String value)
- Se puede acceder a este valor en cualquier Mapeador/Reductor usando el método get()
Configuration conf = context.getConfiguration(); // we will store value in String variable String value = conf.get(String name);