En este artículo, discutiremos cómo encontrar valores distintos de varias columnas en el marco de datos de PySpark.
Vamos a crear un marco de datos de muestra para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "Tezas", "Google"],
["2", "Mohit Rawat", "Rakuten"],
["3", "rohith", "Geeksforgeeks"],
["4", "Nancy", "IBM"],
["1", "Raghav", "Wipro"],
["4", "Komal", "Amazon"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
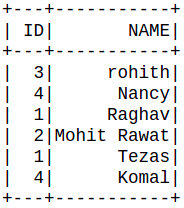
dataframe.show()
Producción:

Método 1: usar el método distinto()
El método distinto() se utiliza para colocar/eliminar los elementos duplicados del marco de datos.
Sintaxis: df.distinct(columna)
Ejemplo 1: obtenga una fila distinta de todos los marcos de datos.
Python3
dataframe.distinct().show()
Producción:

Ejemplo 2: Obtener valor distinto de columnas individuales.
Se puede hacer pasando un solo nombre de columna con marco de datos.
Python3
dataframe.select('NAME').distinct().show()
Producción:

Ejemplo 3: obtener un valor distinto de varias columnas.
Se puede hacer pasando varios nombres de columna como una forma de lista con marco de datos.
Python3
dataframe.select('ID',"NAME").distinct().show()
Método 2: Usando el método dropDuplicates().
dropDuplicates() se usa para eliminar filas que tienen los mismos valores en varias columnas seleccionadas.
Sintaxis: df.dropDuplicates()
Ejemplo 1: obtenga una fila distinta de todos los marcos de datos.
Python3
dataframe.dropDuplicates().show()
Producción:
Ejemplo 2: Obtener valor distinto de columnas individuales.
Se puede hacer pasando un solo nombre de columna con marco de datos.
Python3
dataframe.select("NAME").dropDuplicates().show()
Producción:
Ejemplo 3: obtener un valor distinto de varias columnas.
Se puede hacer pasando varios nombres de columna como una forma de lista con marco de datos.
Python3
dataframe.dropDuplicates(["NAME","ID"]).select(["ID","NAME"]).show()
Producción:

Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA