El servidor MySQL es un sistema de administración de bases de datos relacionales de código abierto que es un soporte importante para las aplicaciones basadas en la web. Las bases de datos y las tablas relacionadas son el componente principal de muchos sitios web y aplicaciones, ya que los datos se almacenan e intercambian a través de la web. Para acceder a bases de datos MySQL desde un servidor web, utilizamos varios módulos en Python como PyMySQL, mysql.connector, etc.
En este artículo, vamos a encontrar valores duplicados en una tabla MySQL específica en una base de datos. Primero, vamos a conectarnos a una base de datos que tenga una tabla MySQL. La consulta SQL que se va a utilizar es:
SELECT * FROM table-name GROUP BY col_1, col_2,..., col_n HAVING COUNT(*) > 1;
Si la tabla tiene una clave principal, también se puede usar la siguiente consulta:
SELECT * FROM table-name GROUP BY primar-key HAVING COUNT(*) > 1;
Las consultas anteriores generarán solo filas duplicadas en una tabla, y luego estas filas se mostrarán como salida.
A continuación se muestran algunos programas que muestran cómo encontrar valores duplicados en una tabla MySQL específica en una base de datos:
Ejemplo 1
A continuación se muestra la tabla Documental en la base de datos geek a la que se accederá mediante un script de Python:
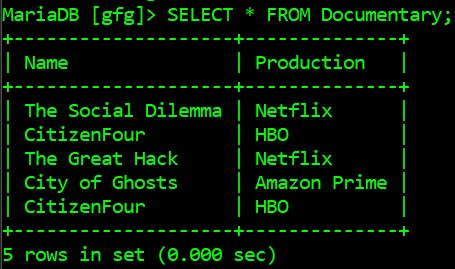
A continuación se muestra el programa para obtener las filas duplicadas en la tabla MySQL:
Python3
# import required module
import mysql.connector
# connect python with mysql with your hostname,
# database, user and password
db = mysql.connector.connect(host='localhost',
database='gfg',
user='root',
password='')
# create cursor object
cursor = db.cursor()
# get the sum of rows of a column
cursor.execute("SELECT * FROM Documentary \
GROUP BY Name, Production \
HAVING COUNT(*) > 1;")
# fetch duplicate rows and display them
print('Duplicate Rows:')
for row in cursor.fetchall(): print(row)
# terminate connection
db.close()
Producción:
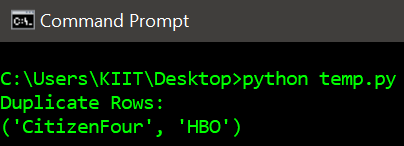
Ejemplo 2:
Aquí hay otro ejemplo para encontrar las filas duplicadas de una tabla en una base de datos determinada, a continuación se muestra el esquema de la tabla y las filas:
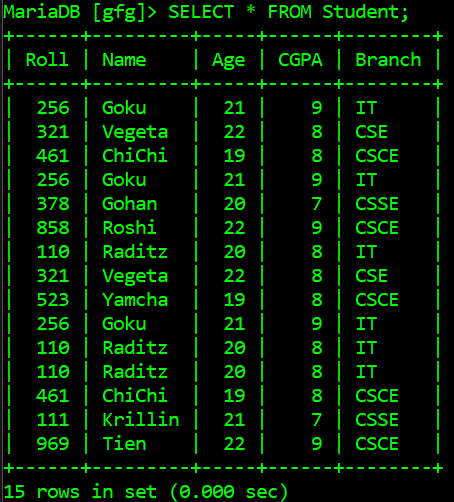
Como podemos ver, el atributo Roll es la clave principal de la tabla Student , por lo tanto, solo se puede usar con la declaración GROUP BY en la consulta para generar las filas duplicadas, a continuación se muestra el script de Python para obtener el recuento de filas de la tabla Student :
Python3
# import required module
import mysql.connector
# connect python with mysql with your hostname,
# database, user and password
db = mysql.connector.connect(host='localhost',
database='gfg',
user='root',
password='')
# create cursor object
cursor = db.cursor()
# get the sum of rows of a column
cursor.execute("SELECT * FROM Student \
GROUP BY Roll \
HAVING COUNT(*) > 1;")
# fetch duplicate rows and display them
print('Duplicate Rows:')
for row in cursor.fetchall(): print(row)
# terminate connection
db.close()
Producción:
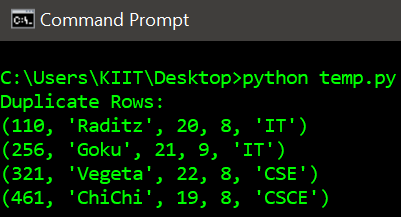
Publicación traducida automáticamente
Artículo escrito por riturajsaha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA