En este artículo, aprenderemos cómo estandarizar los datos en un Dataframe de Pandas.
La estandarización es un concepto muy importante en el escalado de características, que es una parte integral de la ingeniería de características. Cuando recopile datos para el análisis de datos o el aprendizaje automático, tendremos muchas funciones, que son funciones independientes. Con la ayuda de las funciones independientes, intentaremos predecir la función dependiente en el aprendizaje supervisado. Mientras ve los datos, si ve que habrá más ruido en los datos, lo que pondrá al modelo en riesgo de verse influenciado por los valores atípicos. Entonces, para esto, normalmente normalizaremos o estandarizaremos los datos. Ahora analicemos más a fondo el tema de la estandarización.
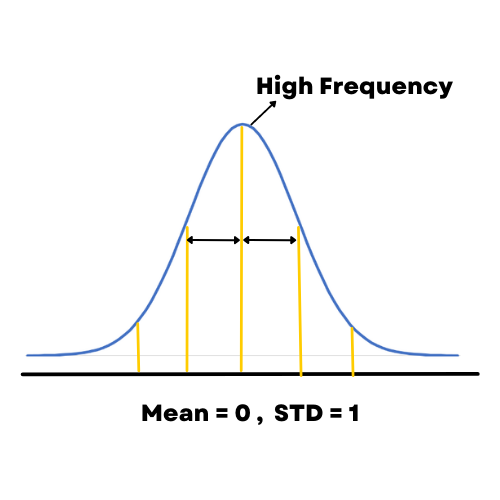
Es otro proceso para reducir los datos y facilitar que el modelo de aprendizaje automático aprenda de ellos. En este método, intentaremos reducir la media a ‘0’ y la desviación estándar a ‘1’.
Otra cosa importante que debe saber es que cuando normaliza los datos, los valores se reducirán a un rango específico que va de 0 a 1. En la estandarización, no hay límites específicos para que los datos se reduzcan.
Método 1: Implementación en pandas [Z-Score]
Para estandarizar los datos en pandas, Z-Score es un método muy popular en pandas que se usa para estandarizar los datos. Z-Score nos dirá a cuántas desviaciones estándar se encuentra un valor de la media. cuando estandaricemos los datos, los datos se cambiarán a una forma específica donde el gráfico de su frecuencia formará una curva de campana. La fórmula para convertir los datos es,
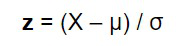
Sintaxis:
df[‘columna’] =( df[‘columna’] – df[‘columna’].mean() ) / df[‘columna’].std()
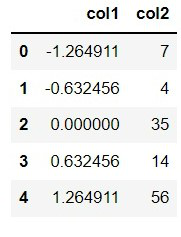
En este método, vamos a estandarizar la primera columna del conjunto de datos usando las funciones integradas de pandas mean() y std() que darán la media y las desviaciones estándar de los datos de la columna. Entonces, usar un cálculo simple de restar el elemento con su media y dividirlos con la desviación estándar nos dará la puntuación z de los datos, que son los datos estandarizados.
Trama de datos en uso:
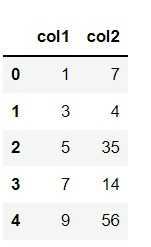
Ejemplo: estandarización de datos
Python3
# Importing the library
import pandas as pd
# Creating the data frame
details = {
'col1': [1, 3, 5, 7, 9],
'col2': [7, 4, 35, 14, 56]
}
# creating a Dataframe object
df = pd.DataFrame(details)
# Z-Score using pandas
df['col1'] = (df['col1'] - df['col1'].mean()) / df['col1'].std()
Producción:
Método 2: Usar scipy.stats()
Scipy es una biblioteca de cálculos científicos. Puede manejar sin ayuda cualquier cálculo matemático complejo. Como todos los cálculos, Scipy también puede manejar cálculos estadísticos para que podamos encontrar el puntaje z de cualquier columna con solo una línea de código.
Sintaxis:
scipy.stats.zscore( df[‘columna’] )
Ahora vamos a estandarizar la segunda columna de nuestros datos al encontrar el puntaje z usando scipy.stats.zscore() solo necesitamos mencionar la columna y la biblioteca se encargará de todo.
Ejemplo: estandarización de valores
Python
# Importing the library
import pandas as pd
import scipy
from scipy import stats
# Creating the data frame
details = {
'col1': [1, 3, 5, 7, 9],
'col2': [7, 4, 35, 14, 56]
}
# creating a Dataframe object
df = pd.DataFrame(details)
# Z-Score using scipy
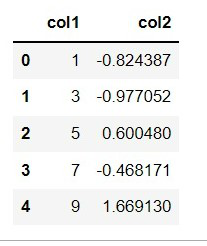
df['col2'] = stats.zscore(df['col2'])
Producción:
Método 3: Usar sci-kit learn Escalador estándar
Sci-kit gain es una biblioteca de creación de modelos y aprendizaje automático. Podemos realizar muchas operaciones en esta biblioteca, como preprocesamiento, análisis y también creación de modelos para todo tipo de aprendizaje automático, como problemas de aprendizaje supervisado y no supervisado. En esta biblioteca, se usa un método de preprocesamiento llamado standardscaler() para estandarizar los datos.
Sintaxis:
escalador = StandardScaler()
df = escalador.fit_transform(df)
En este ejemplo, vamos a transformar todos los datos en una forma estandarizada. Para hacerlo, primero debemos crear un objeto standardscaler() y luego ajustar y transformar los datos.
Ejemplo: estandarización de valores
Python
# Importing the library
import pandas as pd
from sklearn.preprocessing import StandardScaler
# Creating the data frame
details = {
'col1': [1, 3, 5, 7, 9],
'col2': [7, 4, 35, 14, 56]
}
# creating a Dataframe object
df = pd.DataFrame(details)
# define standard scaler
scaler = StandardScaler()
# transform data
df = scaler.fit_transform(df)
Producción:

Publicación traducida automáticamente
Artículo escrito por shivapriya1726 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA