La regresión lineal es un método de análisis predictivo en el aprendizaje automático. Básicamente se utiliza para comprobar dos cosas:
- Si un conjunto de variables predictoras (independientes) hace un buen trabajo al predecir la variable de resultado (dependiente).
- Cuáles de las variables predictoras son significativas en términos de predecir la variable de resultado y de qué manera, lo cual está determinado por la magnitud y el signo de las estimaciones respectivamente.
La regresión lineal se usa con una variable de resultado y una o más de una variable predictora. La regresión lineal simple funcionará con un resultado y una variable predictora. El modelo de regresión lineal simple es esencialmente una ecuación lineal de la forma y = c + b*x ; donde y es la variable dependiente (resultado), x es la variable independiente (predictor), b es la pendiente de la línea; también conocido como coeficiente de regresión y c es la intersección; etiquetada como constante.
Una línea de regresión lineal es una línea que se ajusta mejor al gráfico entre la variable predictora (independiente) y la variable pronosticada (dependiente).
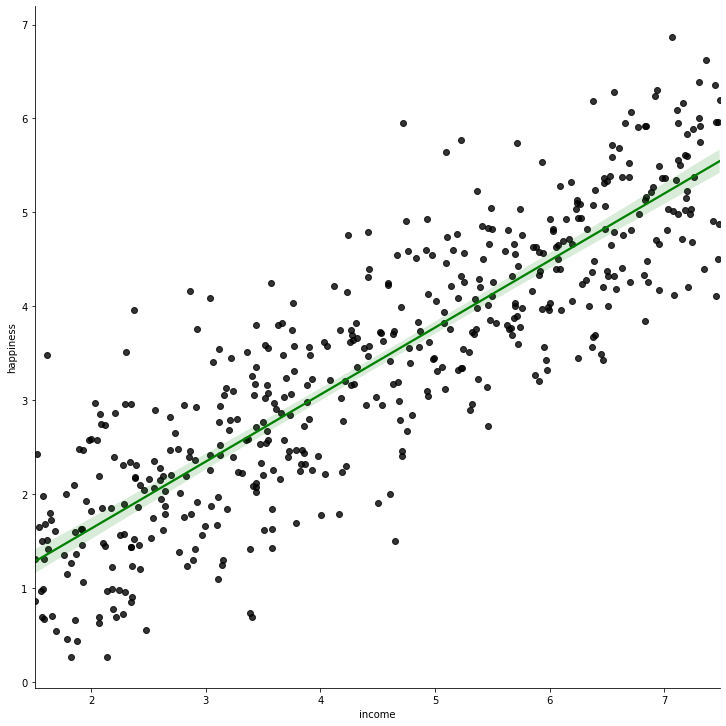
Línea de regresión (verde continua) para el conjunto de datos de ingresos frente a felicidad
En el diagrama anterior, la línea verde es la línea de mejor ajuste; y se toma como la línea de regresión para el conjunto de datos dado.
Uno de los métodos más populares para decidir la línea de regresión es el método de mínimos cuadrados. Este método esencialmente funciona para encontrar la línea que mejor se ajusta a los datos al minimizar la suma de los cuadrados de las desviaciones verticales de cada punto de datos (la desviación de un punto que reside en la línea es 0). Como las desviaciones se elevan al cuadrado, no hay cancelación entre los valores positivo y negativo de la desviación.
Acercarse:
- Seleccione un enunciado del problema adecuado para la regresión lineal. Estaremos seleccionando income.data_ .
- Instale y cargue los paquetes para el trazado/visualización. Puede visualizar los puntos de datos para ver si los datos son adecuados para la regresión lineal.
- Lea el conjunto de datos en un marco de datos. También puede visualizar el marco de datos después de la lectura (ejemplo que se muestra en el código a continuación).
- Cree un modelo de regresión lineal a partir de los datos utilizando la función lm() . Almacene el modelo creado en una variable.
- Explora el modelo.
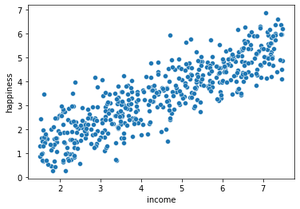
Diagrama de dispersión después de graficar las variables dependientes e independientes entre sí
Paso 1: Instale y cargue los paquetes necesarios. Lea y explore el conjunto de datos. También puede establecer el directorio de trabajo del cuaderno usando la función setwd() , pasando la ruta del directorio (donde se almacena el conjunto de datos) como argumento.
R
# install the packages and load them
install.packages("ggplot2")
install.packages("tidyverse")
library(ggplot2)
library(tidyverse)
# Read the data into a data frame
dataFrame <- read.csv("income_data.csv")
# Explore the data frame
head(dataFrame)
Producción:
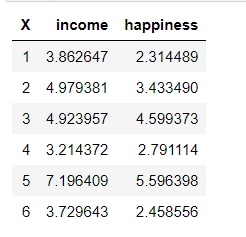
Paso 2: Separar las variables del conjunto de datos. Visualice el conjunto de datos.
R
# Allocate the columns to different variables # x is the independent variable x <- dataFrame$income # y is the dependent variable y <- dataFrame$happiness # Plot the graph between dependent and independent variable plot(x, y)
Producción:
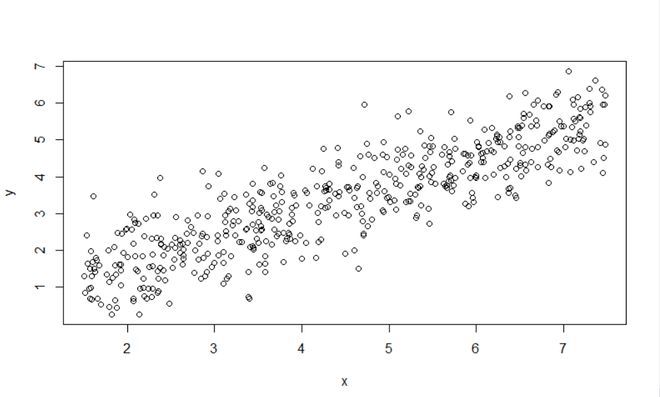
Gráfica de X (Ingresos) vs Y (Felicidad)
Paso 3: borre el modelo de regresión lineal de los datos. Entrenar y ver el modelo.
R
# Create the linear model from the data. # y ~ x denotes y dependent and x is the independent variable model <- lm(y~x) # Print the model to check the intercept model
Producción:
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
0.2043 0.7138
Como puedes ver, el valor del intercepto es 0.2043. Pero, ¿cómo obtener este valor en una variable?
Extrayendo los valores de intercepción
Podemos usar un resumen del modelo creado para extraer el valor de la intersección.
Código:
R
model_summary <- summary(model) intercept_value <- model_summary$coefficients[1,1] intercept_value
Producción:
0.204270396204177
Si intenta imprimir el resumen de la variable del modelo (model_summary), verá los coeficientes a continuación. Es una array 2D, que almacena todos los coeficientes mencionados. Por lo tanto, [1,1] corresponderá al intercepto predicho (de la línea de regresión).
R
model_summary <- summary(model) model_summary
Producción:
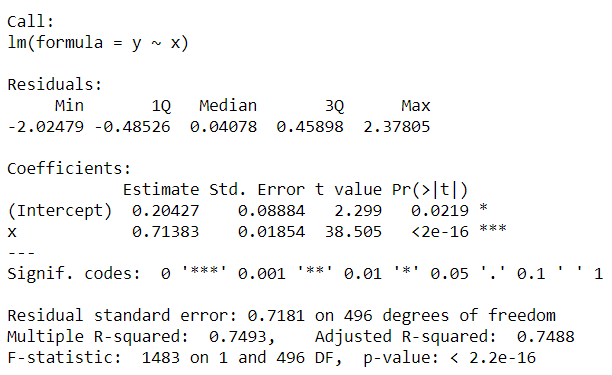
Así extraemos el valor del intercepto de un modelo de regresión lineal en R.
Publicación traducida automáticamente
Artículo escrito por naphadesahil y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA