Normalmente, estamos trabajando con archivos de Excel y seguramente nos hemos encontrado con un escenario en el que necesitamos fusionar varios archivos de Excel en uno solo. El método tradicional siempre ha sido usar un código VBA dentro de Excel que hace el trabajo pero es un proceso de varios pasos y no es tan fácil de entender. Otro método es copiar manualmente archivos largos de Excel en uno que no solo consume mucho tiempo, es problemático sino que también es propenso a errores.
Esta tarea se puede hacer fácil y rápidamente con pocas líneas de código en Python con el módulo Pandas . Primero, necesitamos instalar el módulo con pip. Así que dejemos la instalación fuera de nuestro camino.
Utilice el siguiente comando en la terminal:
pip install pandas
Método 1: Usando dataframe.append()
La función pandas dataframe.append() se usa para agregar filas de otro marco de datos al final del marco de datos dado, devolviendo un nuevo objeto de marco de datos. Las columnas que no están en los marcos de datos originales se agregan como nuevas columnas y las nuevas celdas se completan con el valor de NaN.
Sintaxis: DataFrame.append(otro, ignore_index=Falso, verificar_integridad=Falso, ordenar=Ninguno)
Parámetros:
- otro: DataFrame o Series/objeto similar a dict, o una lista de estos
- ignore_index : si es verdadero, no use las etiquetas de índice. predeterminado Falso.
- verificar_integridad: si es verdadero, genera ValueError al crear un índice con duplicados. predeterminado Falso.
- sort : ordena las columnas si las columnas de self y other no están alineadas. predeterminado Falso.
Devoluciones : DataFrame adjunto
Ejemplo:
Excel utilizado: FoodSales1-1 , FoodSales2-1
Python3
# importing the required modules
import glob
import pandas as pd
# specifying the path to csv files
path = "C:/downloads"
# csv files in the path
file_list = glob.glob(path + "/*.xlsx")
# list of excel files we want to merge.
# pd.read_excel(file_path) reads the excel
# data into pandas dataframe.
excl_list = []
for file in file_list:
excl_list.append(pd.read_excel(file))
# create a new dataframe to store the
# merged excel file.
excl_merged = pd.DataFrame()
for excl_file in excl_list:
# appends the data into the excl_merged
# dataframe.
excl_merged = excl_merged.append(
excl_file, ignore_index=True)
# exports the dataframe into excel file with
# specified name.
excl_merged.to_excel('total_food_sales.xlsx', index=False)
Producción :
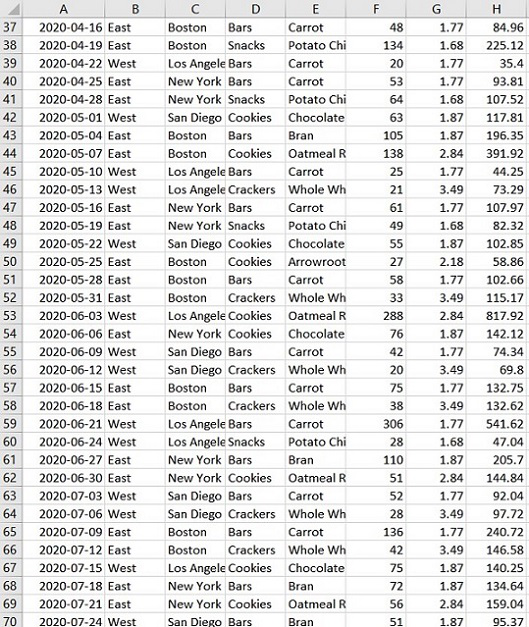
‘total_food_sales.xlsx’
Método 2: Usar pandas.concat()
La función pandas.concat() hace todo el trabajo pesado de realizar operaciones de concatenación junto con un eje de objetos Pandas mientras realiza una lógica de conjunto opcional (unión o intersección) de los índices (si los hay) en los otros ejes.
Sintaxis: concat(objs, eje, unir, ignorar_índice, claves, niveles, nombres, verificar_integridad, ordenar, copiar)
Parámetros:
- objs: Objetos Series o DataFrame
- eje: eje a lo largo del cual concatenar; predeterminado = 0 //a lo largo de las filas
- join: forma de manejar índices en otro eje; predeterminado = ‘exterior’
- ignore_index: si es Verdadero, no use los valores de índice a lo largo del eje de concatenación; predeterminado = Falso
- teclas: secuencia para agregar un identificador a los índices de resultados; predeterminado = Ninguno
- niveles: niveles específicos (valores únicos) a usar para construir un MultiIndex; predeterminado = Ninguno
- nombres: nombres de los niveles en el índice jerárquico resultante; predeterminado = Ninguno
- verificar_integridad: verificar si el nuevo eje concatenado contiene duplicados; predeterminado = Falso
- ordenar: ordenar el eje de no concatenación si aún no está alineado cuando la unión es ‘externa’; predeterminado = Falso
- copiar: si es Falso, no copiar datos innecesariamente; predeterminado = Verdadero
Devoluciones: un marco de datos de pandas con datos concatenados.
Ejemplo:
En el último ejemplo, trabajamos en solo dos archivos de Excel con unas pocas filas. Intentemos fusionar más archivos, cada uno con aproximadamente 5000 filas y 7 columnas. Tenemos 5 archivos BankE , BankD , BankC , BankB , BankA con datos históricos de acciones para el banco respectivo. Vamos a fusionarlos en un solo archivo ‘Bank_Stocks.xlsx’. Aquí estamos usando el método pandas.concat().
Python3
# importing the required modules
import glob
import pandas as pd
# specifying the path to csv files
path = "C:/downloads"
# csv files in the path
file_list = glob.glob(path + "/*.xlsx")
# list of excel files we want to merge.
# pd.read_excel(file_path) reads the
# excel data into pandas dataframe.
excl_list = []
for file in file_list:
excl_list.append(pd.read_excel(file))
# concatenate all DataFrames in the list
# into a single DataFrame, returns new
# DataFrame.
excl_merged = pd.concat(excl_list, ignore_index=True)
# exports the dataframe into excel file
# with specified name.
excl_merged.to_excel('Bank_Stocks.xlsx', index=False)
Producción :
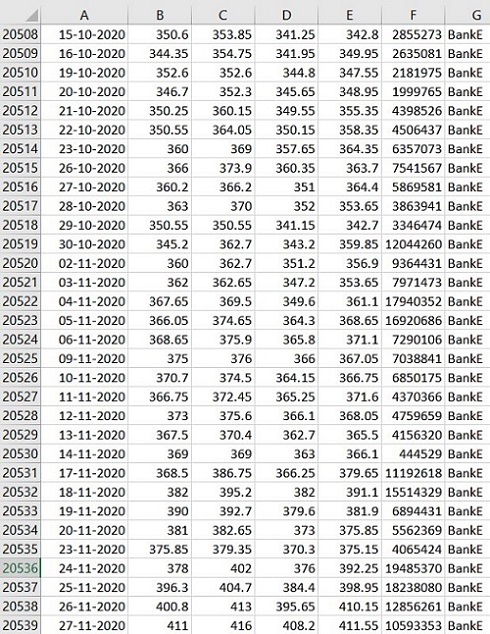
Acciones_Banco.xlsx
Publicación traducida automáticamente
Artículo escrito por pansaripulkit13 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA