El análisis de componentes principales (PCA) en la programación R es el análisis de los componentes lineales de todos los atributos existentes. Los componentes principales son combinaciones lineales (transformación ortogonal) del predictor original en el conjunto de datos. Es una técnica útil para EDA (análisis exploratorio de datos) y le permite visualizar mejor las variaciones presentes en un conjunto de datos con muchas variables.
Los componentes de los datos se calculan y se utilizan para realizar un cambio de base en los datos, a veces utilizando solo los primeros componentes principales e ignorando el resto. Uno puede tomar PCA como un tipo de transformación lineal de los datos sobre la base de ciertos espacios de datos. Esta transformación ajusta los datos en un sistema de coordenadas donde la varianza más significativa se encuentra en la primera coordenada, y cada coordenada subsiguiente es ortogonal a la última y tiene una varianza menor que la anterior.
Parcela PCA en R
Vamos a trabajar en el conjunto de datos ‘Iris’, que está integrado en R. Es un conjunto de datos multivariado que consta de datos de 50 muestras de cada una de las tres especies de Iris (Iris setosa, Iris virginica e Iris versicolor).
R
# structure of the iris # dataset str(iris) # print the iris dataset head(iris)
Producción:

Como se mencionó, PCA funciona mejor con datos numéricos, descuidaremos la variable categórica Species. Ahora nos queda una array de 4 columnas y 150 filas que pasaremos a través de la función prcomp() para el análisis de componentes principales. Esta función devuelve los resultados como un objeto de la clase ‘prcomp’. Asignaremos la salida a una variable llamada iris.pca.
R
iris.pca <- prcomp(iris[,c(1:4)], center = TRUE, scale. = TRUE) # summary of the # prcomp object summary(iris.pca)
Producción:
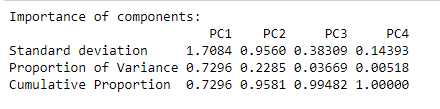
Aquí tenemos cuatro componentes principales llamados PC1-4. Cada uno de estos explica un porcentaje de la variación total en el conjunto de datos. Por ejemplo, PC1 explica casi el 72 % de la varianza total, es decir, alrededor de las tres cuartas partes de la información del conjunto de datos puede encapsularse solo en ese componente principal. PC2 explica el 22% y así sucesivamente.
Echemos un vistazo a la estructura del objeto PCA así formado.
R
# structure of the pca object str(iris.pca)
Producción:

Trazado PCA
Cuando hablamos de trazar un PCA, generalmente nos referimos a un diagrama de dispersión de los dos primeros componentes principales PC1 y PC2. Estos gráficos revelan las características de los datos, como la no linealidad y la desviación de la normalidad. PC1 y PC2 se evalúan para cada vector de muestra y se grafican.
La función autoplot() del ‘paquete ggfortify’ facilita el trazado de PCA en R.
R
# loading library library(ggfortify) iris.pca.plot <- autoplot(iris.pca, data = iris, colour = 'Species') iris.pca.plot
Producción:
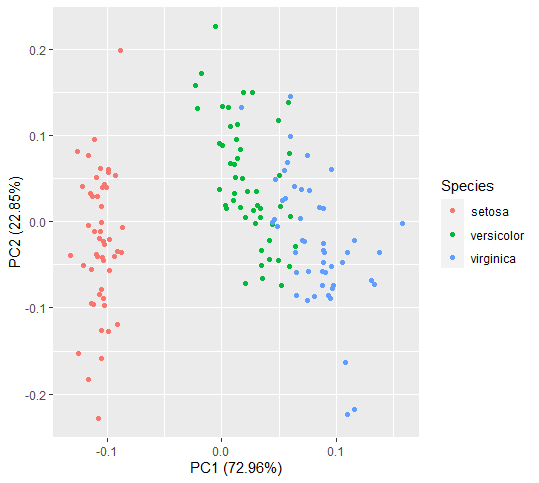
Para una mejor comprensión de la transformación lineal de características, también se puede usar la función biplot() para trazar PCA.
R
biplot.iris.pca <- biplot(iris.pca) biplot.iris.pca
Producción:
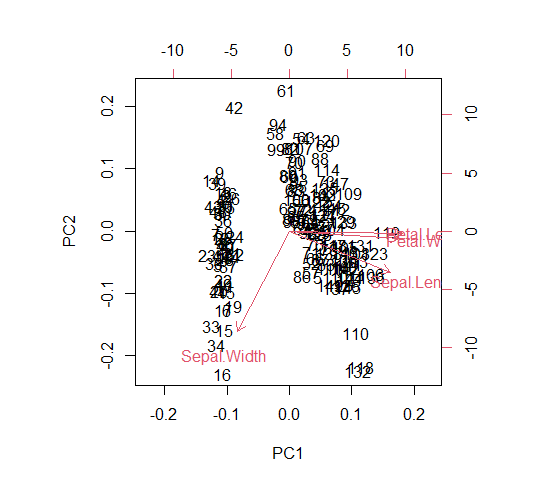
El eje X del biplot representa el primer componente principal donde la longitud y el ancho del pétalo se combinan y se transforman en PC1 con algunas partes de la longitud y el ancho del sépalo. Mientras que la parte vertical de la longitud del sépalo y el ancho del sépalo forman el segundo componente principal.
Para determinar las características ideales que se pueden justificar después de realizar PCA, se puede usar la función plot( ) para trazar el objeto precomp.
R
plot.iris.pca <- plot(iris.pca, type="l") plot.iris.pca
Producción:
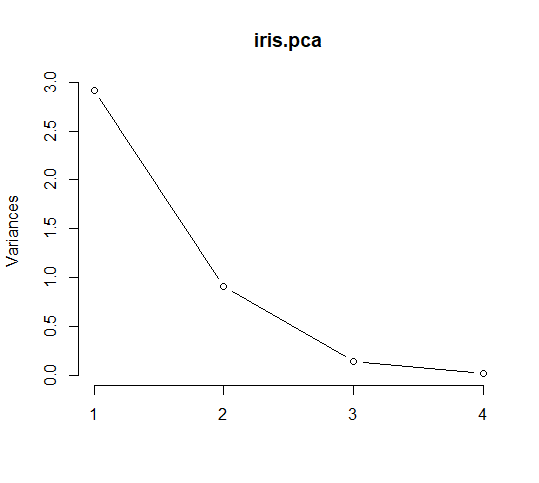
En un screeplot, el ‘brazo doblado’ representa una disminución en la contribución acumulativa. El gráfico anterior muestra la curva en el segundo componente principal.
Publicación traducida automáticamente
Artículo escrito por misraaakash1998 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA