Prerrequisito: FuzzyWuzzy
En este tutorial, aprenderemos cómo hacer coincidencias aproximadas en la columna de pandas DataFrame usando Python. La coincidencia aproximada es un proceso que nos permite identificar las coincidencias que no son exactas pero que encuentran un patrón determinado en nuestro elemento de destino. La coincidencia aproximada es la base de los motores de búsqueda. Es por eso que recibimos muchas recomendaciones o sugerencias cuando escribimos nuestra consulta de búsqueda en cualquier navegador.
Funciones utilizadas
- pd.DataFrame (dict): para convertir un diccionario de python en un marco de datos de pandas
- dataframe[‘column_name’].tolist(): Para convertir una columna particular del marco de datos de pandas en una lista de elementos en python
- append(): para agregar elementos a una lista
- process.extract(query, choice, limit): una función que viene con el módulo de procesamiento de la biblioteca fuzzywuzzy para extraer los elementos de la lista de opciones que coinciden con la consulta dada . El número de opciones más cercanas que se extraen está determinado por el límite establecido por nosotros.
- process.extractOne(query, choice, scorer): extrae la única coincidencia más cercana de la lista de opciones que coincide con la consulta dada y el marcador es el parámetro opcional para que use un marcador particular como fuzz.token_sort_ratio, fuzz.token_set_ratio
- fuzz.ratio: para calcular la relación de similitud entre dos strings en función de la distancia de Levenshtein
- fuzz.partial_ratio: para calcular la relación de strings parciales entre la string más pequeña y todas las substrings de longitud n de la string larga
- fuzz.token_sort_ratio: calcula la relación de similitud después de ordenar los tokens en cada string
- fuzz.token_set_ratio: intenta descartar diferencias en las strings, devuelve la proporción máxima después de calcular la proporción en tres conjuntos de substrings particulares en python
Ejemplos
Ejemplo 1: (Enfoque básico)
- Al principio, crearemos dos diccionarios. Luego, lo convertiremos en marcos de datos de pandas y crearemos dos listas vacías para almacenar las coincidencias más tarde de lo que se muestra a continuación:
Python3
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
import pandas
dict1 = {'name': ["aparna", "pankaj",
"sudhir", "Geeku"]}
dict2 = {'name': ["aparn", "arup", "Pankaj",
"sudhir c", "Geek", "abc"]}
# converting to pandas dataframes
dframe1 = pd.DataFrame(dict1)
dframe2 = pd.DataFrame(dict2)
# empty lists for storing the
# matches later
mat1 = []
mat2 = []
# printing the pandas dataframes
dframe1.show()
dframe2.show()
dframe1:

dframe2:

- Luego, convertiremos los marcos de datos en listas usando la función tolist().
- Tomamos umbral = 80 para que la coincidencia aproximada ocurra solo cuando las strings están al menos más del 80% cerca entre sí.
Python3
list1 = dframe1['name'].tolist() list2 = dframe2['name'].tolist() # taking the threshold as 80 threshold = 80
Producción:

- Luego iteraremos a través de los elementos de list1 para extraer su coincidencia más cercana de list2.
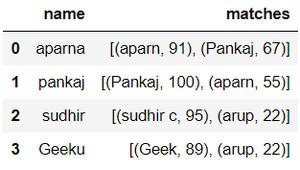
- Aquí usamos la función process.extract() del módulo de procesamiento para extraer los elementos.
- Límite = 2 significa que extraerá los dos elementos más cercanos con su relación de precisión, si lo imprimimos ahora, podemos ver los valores de la relación.
- Luego agregamos cada coincidencia más cercana a la lista mat1
- Y almacene la lista de coincidencias en la columna ‘coincidencias’ en el primer marco de datos, es decir, dframe1
Python3
# iterating through list1 to extract # it's closest match from list2 for i in list1: mat1.append(process.extract(i, list2, limit=2)) dframe1['matches'] = mat1 dframe1.show()
Producción:
- Luego iteraremos nuevamente a través de la columna de coincidencias en el ciclo externo y en el ciclo interno iteramos a través de cada conjunto de coincidencias
- k[1] >= umbral significa que seleccionará solo aquellos elementos cuyo valor de umbral sea mayor o igual a 80 y los agregará a la lista p.
- Con la función “,”.join(), se unen las coincidencias de elementos separadas por una coma si hay más de una coincidencia para un elemento de columna en particular y se agregan a la lista mat2. Establecemos la lista p vacía nuevamente para almacenar las coincidencias del elemento de la siguiente fila en la primera columna del marco de datos.
- Luego almacenamos las coincidencias más cercanas resultantes en dframe1 para obtener nuestro resultado final.
Python3
# iterating through the closest
# matches to filter out the
# maximum closest match
for j in dframe1['matches']:
for k in j:
if k[1] >= threshold:
p.append(k[0])
mat2.append(",".join(p))
p = []
# storing the resultant matches
# back to dframe1
dframe1['matches'] = mat2
dframe1.show()
Producción:

Ejemplo 2:
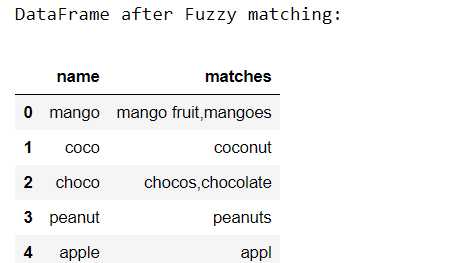
En este ejemplo, los pasos son los mismos que en el ejemplo uno. La única diferencia es que hay varias coincidencias para un elemento de fila en particular, como ‘mango’ y ‘choco’. Establecemos el umbral = 82 para aumentar la precisión de la coincidencia aproximada.
Python3
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# creating the dictionaries
dict1 = {'name': ["mango", "coco", "choco", "peanut", "apple"]}
dict2 = {'name': ["mango fruit", "coconut", "chocolate",
"mangoes", "chocos", "peanuts", "appl"]}
# converting to pandas dataframes
dframe1 = pd.DataFrame(dict1)
dframe2 = pd.DataFrame(dict2)
# empty lists for storing the matches later
mat1 = []
mat2 = []
p = []
# printing the pandas dataframes
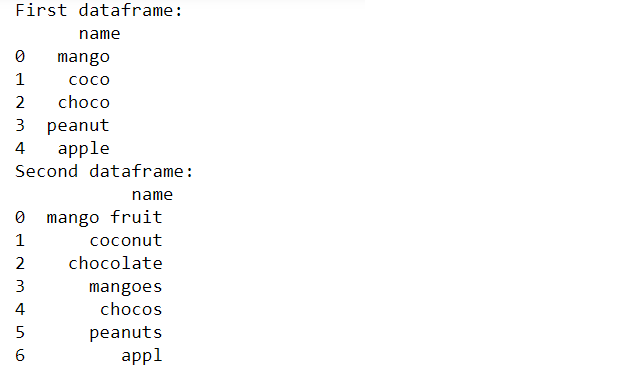
print("First dataframe:\n", dframe1,
"\nSecond dataframe:\n", dframe2)
# converting dataframe column to list
# of elements
# to do fuzzy matching
list1 = dframe1['name'].tolist()
list2 = dframe2['name'].tolist()
# taking the threshold as 82
threshold = 82
# iterating through list1 to extract
# it's closest match from list2
for i in list1:
mat1.append(process.extract(i, list2, limit=2))
dframe1['matches'] = mat1
# iterating through the closest matches
# to filter out the maximum closest match
for j in dframe1['matches']:
for k in j:
if k[1] >= threshold:
p.append(k[0])
mat2.append(",".join(p))
p = []
# storing the resultant matches back to dframe1
dframe1['matches'] = mat2
print("\nDataFrame after Fuzzy matching:")
dframe1
Producción:
Ahora usaremos el método process.extractOne() para hacer coincidir solo el más cercano entre los dos marcos de datos. Dentro de este método aplicaremos diferentes funciones de coincidencia aproximada que son las siguientes:
Ejemplo 3: Usando fuzz.ratio()
Python3
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# creating the dictionaries
dict1 = {'name': ["aparna", "pankaj", "sudhir",
"Geeku", "geeks for geeks"]}
dict2 = {'name': ["aparn", "arup", "Pankaj",
"for geeks geeks", "sudhir c",
"geeks geeks"]}
# converting to pandas dataframes
dframe1 = pd.DataFrame(dict1)
dframe2 = pd.DataFrame(dict2)
# empty lists for storing the matches
# later
mat1 = []
mat2 = []
p = []
# printing the pandas dataframes
print("First dataframe:\n", dframe1,
"\nSecond dataframe:\n", dframe2)
# converting dataframe column to
# list of elements
# to do fuzzy matching
list1 = dframe1['name'].tolist()
list2 = dframe2['name'].tolist()
# taking the threshold as 80
threshold = 80
# iterating through list1 to extract
# it's closest match from list2
for i in list1:
mat1.append(process.extractOne(i, list2, scorer=fuzz.ratio))
dframe1['matches'] = mat1
# iterating through the closest matches
# to filter out the maximum closest match
for j in dframe1['matches']:
if j[1] >= threshold:
p.append(j[0])
mat2.append(",".join(p))
p = []
# storing the resultant matches back to dframe1
dframe1['matches'] = mat2
print("\nDataFrame after Fuzzy matching using fuzz.ratio():")
dframe1
Producción:

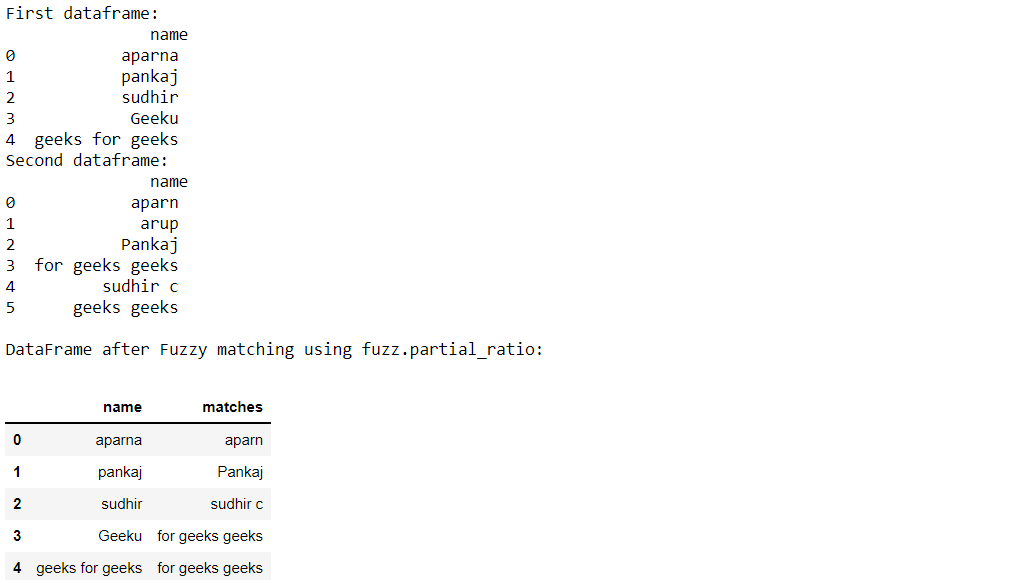
Ejemplo 4: Usando fuzz.partial_ratio()
Python3
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# creating the dictionaries
dict1 = {'name': ["aparna", "pankaj", "sudhir",
"Geeku", "geeks for geeks"]}
dict2 = {'name': ["aparn", "arup", "Pankaj",
"for geeks geeks", "sudhir c",
"geeks geeks"]}
# converting to pandas dataframes
dframe1 = pd.DataFrame(dict1)
dframe2 = pd.DataFrame(dict2)
# empty lists for storing the matches
# later
mat1 = []
mat2 = []
p = []
# printing the pandas dataframes
print("First dataframe:\n", dframe1,
"\nSecond dataframe:\n", dframe2)
# converting dataframe column to
# list of elements
# to do fuzzy matching
list1 = dframe1['name'].tolist()
list2 = dframe2['name'].tolist()
# taking the threshold as 80
threshold = 80
# iterating through list1 to extract
# it's closest match from list2
for i in list1:
mat1.append(process.extractOne(
i, list2, scorer=fuzz.partial_ratio))
dframe1['matches'] = mat1
# iterating through the closest matches
# to filter out the maximum closest match
for j in dframe1['matches']:
if j[1] >= threshold:
p.append(j[0])
mat2.append(",".join(p))
p = []
# storing the resultant matches back to dframe1
dframe1['matches'] = mat2
print("\nDataFrame after Fuzzy matching using fuzz.partial_ratio:")
dframe1
Producción:
Ejemplo 5: Uso de fuzz.token_sort_ratio()
Python3
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# creating the dictionaries
dict1 = {'name': ["aparna", "pankaj", "sudhir",
"Geeku", "geeks for geeks"]}
dict2 = {'name': ["aparn", "arup", "Pankaj",
"for geeks geeks", "sudhir c",
"Geek"]}
# converting to pandas dataframes
dframe1 = pd.DataFrame(dict1)
dframe2 = pd.DataFrame(dict2)
# empty lists for storing the matches
# later
mat1 = []
mat2 = []
p = []
# printing the pandas dataframes
print("First dataframe:\n", dframe1,
"\nSecond dataframe:\n", dframe2)
# converting dataframe column to
# list of elements
# to do fuzzy matching
list1 = dframe1['name'].tolist()
list2 = dframe2['name'].tolist()
# taking the threshold as 80
threshold = 80
# iterating through list1 to extract
# it's closest match from list2
for i in list1:
mat1.append(process.extractOne(
i, list2, scorer=fuzz.token_sort_ratio))
dframe1['matches'] = mat1
# iterating through the closest matches
# to filter out the maximum closest match
for j in dframe1['matches']:
if j[1] >= threshold:
p.append(j[0])
mat2.append(",".join(p))
p = []
# storing the resultant matches back
# to dframe1
dframe1['matches'] = mat2
print("\nDataFrame after Fuzzy matching using fuzz.token_sort_ratio:")
dframe1
Producción:
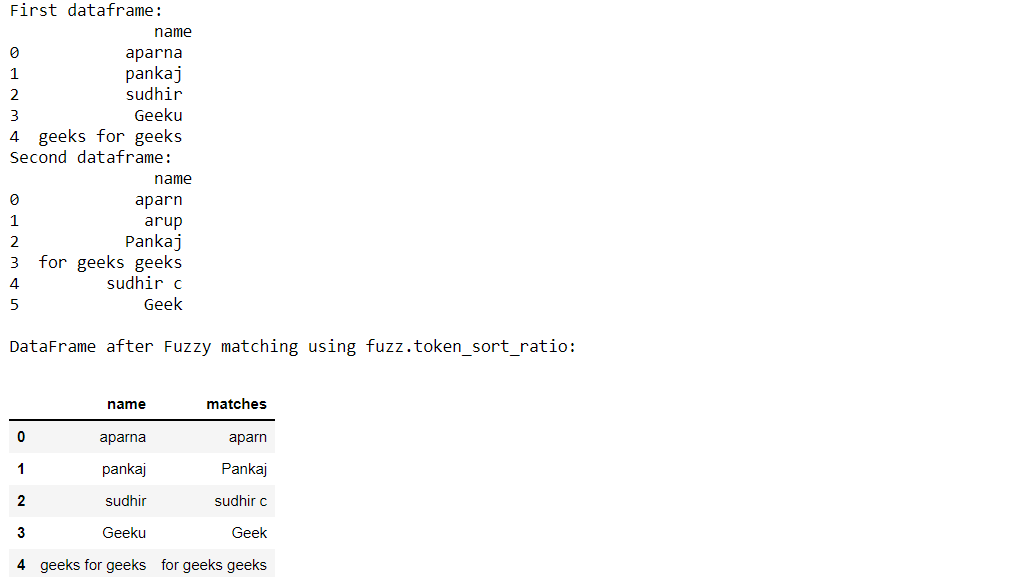
Ejemplo 6: Uso de fuzz.token_set_ratio()
Python3
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# creating the dictionaries
dict1 = {'name': ["aparna", "pankaj", "Geeku",
"geeks for geeks"]}
dict2 = {'name': ["aparn", "arup", "Pankaj",
"geeks for for geeks",
"geeks for geeks", "Geek"]}
# converting to pandas dataframes
dframe1 = pd.DataFrame(dict1)
dframe2 = pd.DataFrame(dict2)
# empty lists for storing the matches
# later
mat1 = []
mat2 = []
p = []
# printing the pandas dataframes
print("First dataframe:\n", dframe1,
"\nSecond dataframe:\n", dframe2)
# converting dataframe column
# to list of elements
# to do fuzzy matching
list1 = dframe1['name'].tolist()
list2 = dframe2['name'].tolist()
# taking the threshold as 80
threshold = 80
# iterating through list1 to extract
# it's closest match from list2
for i in list1:
mat1.append(process.extractOne(
i, list2, scorer=fuzz.token_set_ratio))
dframe1['matches'] = mat1
# iterating through the closest matches
# to filter out the maximum closest match
for j in dframe1['matches']:
if j[1] >= threshold:
p.append(j[0])
mat2.append(",".join(p))
p = []
# storing the resultant matches back
# to dframe1
dframe1['matches'] = mat2
print("\nDataFrame after Fuzzy matching using token_set_ratio():")
dframe1
Producción:

Publicación traducida automáticamente
Artículo escrito por rijushree100guha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA